From User Requirements to Actionable Tickets
Why is This Important?
When people think of software developers, they think of someone who writes code all day long. While writing code is one of the main tasks of a developer, many developers spend lots of time on other activities. These activities enable us to get to the point where we can write the code, or make sure that the code that we write is useful. In most teams, it is up to the Senior Developers to guide these activities to ensure that all of the developers have clear and actionable tickets.
In this chapter, we cover how can go from vague or abstract requirements to actionable tickets, by breaking down the process into several stages.
The Work Cycle of a Developer
As we mentioned in the introduction most software developers are used to a fairly simple work cycle in their day-to-day:

However, this assumes that the tickets have already been created. The person in charge of creating the tickets will vary from team to team. But in most teams, the Sr. Developers will at least have an active role in defining the scope of these tickets, and how large chunks of work will be divided into digestible tickets. At most, the Sr. Developer will have an active role in identifying and analyzing the user requirements. In this chapter, we will cover how we can create better tickets starting from raw user requirements.
Using a Structured Approach
Going from user requirements to actionable tickets can seem like a daunting endeavor. And like any big endeavor, it helps to break down the process into a structured approach that we can follow step by step.
The proposed approach can be seen in the diagram below:

Some of these terms can have different meanings depending on the context, so we'll define a common language that we'll be using throughout the book. Your organization or team might use slightly different meanings, so it's important to take the context into account.
- User Requirements: requirements set by the end user.
- User Journey: a set of steps a user takes to accomplish a goal.
- Epic: a large body of work with a unifying theme.
- Ticket: the smallest unit of work a developer undertakes.
Keep in mind that going from user requirements to actionable tickets is more an art than a science. The process also requires negotiation to determine what is technically feasible and valuable based on cost/benefit analysis. Not every feature request can be delivered within a reasonable timeframe or with limited resources. A Senior Developer must be willing to listen to other stakeholders and negotiate a lot of ambiguity to distill the high-quality tickets on top of which successful software is built.
User Requirements
User requirements are, as the name implies, the requirements set by the end user. Alternatively, they can be the requirements set by someone else on behalf of the user, sometimes with limited input from the user.
In general, who provides the user requirements?
- Users
- Product Owners
- Business Analysts
- Q/A Team
In cases where the user requirements are provided by someone other than the actual end user, how do we gather data to ensure we're really representing what the user wants? Many techniques exist to accomplish this goal:
- Surveys
- Interviews or focus groups with users
- User Observation
- Usage Data Collection
Other times, the features ideated in brainstorming sessions, where subject matter experts put together their collective creativity to come up with the great next innovation.
Sometimes the requirements we receive as a Software Developer are very detailed. Other times we will get very abstract or vague requirements, that read more like a wishlist.
In the worst case, we will receive non-actionable user requirements. For example:
- We want to improve the application
- We want our users to be more engaged
- We want our applications to be easier to use
In cases where we get these non-actionable requirements, we need to push back and either get more information or discard requirements that won't be translatable into any tangible work. As developers, we use our code to achieve goals, but our code can't bridge gaps in the vision of an organization. These user requirements must be identified early in the process and sent back or discarded.
User Journeys
Mapping user journeys is best done in sessions with representatives from the different areas that are affected by a particular application or piece of functionality.
This can be done in a whiteboard, to allow a more inclusive environment and provide a more holistic view of the different requirements and how they relate to each other.
In these sessions, our objective is to document three critical pieces of information for each requirement:
- Who? Who is the user that is acting?
- What? What is the user trying to accomplish?
- How? How is the user going to achieve their goal?
Brainstorming will normally result in a series of users, goals, and steps. At the brainstorming phase, it's important to try to capture all of the proposed ideas, they can be refined at a later stage.
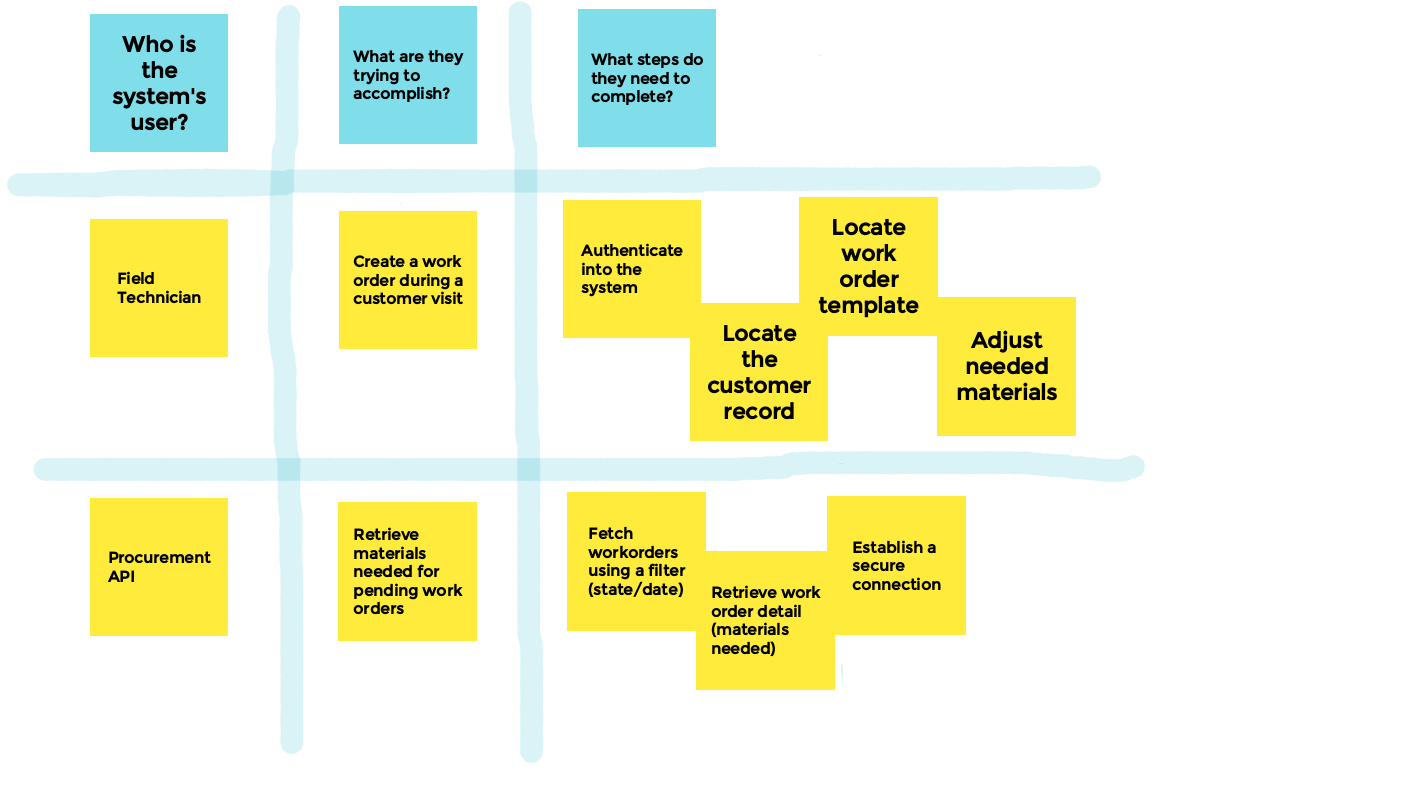
Once there are enough users, goals, and steps on the board, the next step is to organize them. Group together the ones that share common themes, and combine redundant ones.
Once the users, goals, and sets of steps are organized, and depending on the number of ideas up on the board, this might be a good time to take some time and vote for the ones that the team feels are most valuable.
If there's a feeling that ideas are still not properly represented on the board, you can repeat the brainstorming process until the group is satisfied.
Documenting User Journeys
Once some level of consensus has been achieved, it's important to document the user journeys in a non-ambiguous manner. Remember that one of the critical objectives of a user journey mapping session is to create a shared understanding of the user requirements. Even if there are detractors regarding a particular user journey, it's valuable to have a shared understanding. Objections can be better addressed when the specifics are clear to all parties involved.
Both activity diagrams and sequence diagrams can be used to show actions and relationships.
Activity diagrams show the order or flow of operations in a system, while a sequence diagram shows how objects collaborate and focuses on the order or time in which they happen. Generally, sequence diagrams can better illustrate complicated use cases where asynchronous operations take place.
Here we see an example sequence diagram:

Sequence diagrams can be stored as code. Storing diagrams as code makes it easier to share across the team and iterate. Someone with experience can quickly edit sequence diagrams on the fly, helping visualize the flow in real-time as a group of subject matter experts watches.
@startuml
actor "Actor" as Act1
participant "Component" as App
Act1 -> App : Message
App --> Act1: Response
Act1 ->> App : Async Message
App --> Act1: Async Response
loop while done!=true
Act1 -> App: Message
App --> Act1: Response
end
@enduml
Example sequence diagram:

Remember each user journey should tell us:
- Who is the user?
- What are they trying to accomplish?
- What steps do they need to complete?
At this point, you might have a lot of User Journeys. The next step would be to improve the focus by ranking them based on their relative importance to the organization. The ranking can be done by having the SMEs vote on their priorities, or maybe there's a product owner who has the responsibility to set priorities.
Creating Epics
Epics are a large body of work with a unifying theme. In this section, we will focus on epics that are derived from the functionality defined in user journeys, to continue the series of steps to go from user requirements to actionable tickets.
However, in the real world, epics might be defined differently and have different themes. For example, could be an Epic to encompass the work needed to make a release on a particular date, or an epic to remediate a shortcoming in an existing piece of software.
When talking about epics, we have to understand the context in which we are going to be developing the functionality described in an epic.
For example, is our software greenfield or brownfield?
- Greenfield: A project that starts from scratch and is not constrained by existing infrastructure or the need to integrate with legacy systems.
- Brownfield: Work on an existing application, or work on a new application that is severely constrained by how it has to integrate with legacy systems or infrastructure.
Is the software in active development, or just under maintenance?
- Active Development: A project where we're adding new features is considered in active development. These new features can be added either as part of the initial development or subsequent enhancements added after going into production. It is expected that new features will provide new value.
- Maintenance: A project where no new features are being added is considered to be in maintenance. Changes to software under maintenance are limited to bug fixes, security updates, changes to adhere to changing regulations, or the minimum changes needed to keep up with changing upstream or downstream dependencies. No new value is expected to be gained from the maintenance, but rather just a need to remain operational.
Based on the work we did documenting user journeys, we can use these user journeys as the basis for our epics. We can start creating one epic per user journey. Normally an epic will have enough scope to showcase a discreet piece of functionality, more than enough to create a sizeable number of tickets. As we work on planning or creating the tickets, it will become evident that there is overlap across some of the epics. It's important to identify these overlaps and extract them into standalone epics (or tickets as part of existing epics) The disconnect between how we construct user journeys, and how the software has to be built will always result in dependencies we have to manage.
For example, if we had an epic to create a new work order, they might look something like this:
- Epic: A Field Tech needs to create a new work order
- Ticket: Create authentication endpoint
- Ticket: Create an endpoint to search for customers
- Ticket: Create an endpoint to search work order templates
- Ticket: Create an endpoint to adjust materials
- Epic: A Customer Service Rep needs to create an appointment
- Ticket: Create an authentication endpoint
- Ticket: Create an endpoint to search for field techs
- Ticket: Create an endpoint to create an appointment record
It is evident that the first ticket "Create authentication endpoint" is a cross-cutting concern that both epics depend on, but is not limited the either one. And most importantly, we don't want to end up with two different authentication endpoints!
A holistic view is critical to effectively slice up the work into epics and tickets.
If we rearrange the epics and tickets, we can have better-defined epics:
- Epic: A Field Tech needs to create a new work order
Ticket: Create authentication endpoint- Ticket: Create an endpoint to search for customers
- Ticket: Create an endpoint to search work order templates
- Ticket: Create an endpoint to adjust materials
- Epic: A Customer Service Rep needs to create an appointment
Ticket: Create an authentication endpoint- Ticket: Create an endpoint to search for field techs
- Ticket: Create an endpoint to create an appointment record
- Epic: Provide an authentication mechanism
- Ticket: Create an authentication endpoint
Furthermore, we can then add more detail to the epics as we start thinking about the implementation details that might not be fully covered in our user journeys. For example, this might be a good time to add a ticket to manage the users:
- Epic: Provide an authentication mechanism
- Ticket: Create an authentication endpoint
- Ticket: Create user management functionality
There is a dependence on the authentication mechanism. Adjusting for these dependencies is an ever-present challenge. Rather than trying to perfectly align everything in a Gantt Chart to deal with dependencies, we provide a more agile approach in Chapter 4.
- Which epics do we need to create for each Critical User Journeys?
- Do any cross cutting epics need to be created?
- Which tickets will we create for each epic?
Creating Tickets
In the previous section, we have already started talking about creating tickets, in particular, what tickets to create. So in this section, we're going to focus on how the tickets should be created.
In general, a good ticket should have the following attributes:
- Define concrete functionality that can be tested
- Have a completion criteria
- Achievable in a single sprint
The ticket should have enough information describing a concrete piece of functionality. At this stage, the ambiguous and vague ideas that were brainstormed during the user journey brainstorming have to be fleshed out into detailed requirements that can be implemented with code.
As part of the definition of this concrete functionality, we can include:
- Any specifications that must be implemented, for example, API specifications already agreed upon.
- Sample scenarios or test cases that the functionality must be able to pass. These can be used with Behaviour Driven Development.
- Sample data that the functionality will process.
- Detailed diagrams or pseudo-code
- Detailed explanation of the desired functionality
The scope of a single ticket should be testable. At the early stages of development, the testing might be limited to unit testing, as we might depend on external components that are not yet available. For some of the very simple tickets, "testable" might mean something very simple. For example visually verifying that a label has been updated to fix a typo, or that a new button is visible even though there is no logic is attached to the button. To ensure that the scope of the ticket is enough to stand on its own, there should be concrete completion criteria.
To define an actionable completion criteria, you can reference back to the actions that were defined as part of the user journey.
For example, a good completion criteria would look like this:
- Must be accessible at
/customersas aGEToperation. - Must take an arbitrary string as a parameter
q. - Must return any customer records that match the text from the query.
- Matches against all fields in the customer record.
- If no matches, return an empty set.
- Response data format:
{"results": [...]}
Putting it all together an actionable ticket would look like this:
Title: Create endpoint to search for customers
Description:
Create
GETendpoint at/customersthat:
- Is accessible by field techs
- Takes an arbitrary string as parameter "
q"- Matches the string against all fields in customer records
- Returns the list of matching records
- If no matches, return an empty set
- Response data format:
{ "results": [ { "customer_id": "xxx", "first_name": "John", "last_name": "Doe", "email": "john@test.com", "phone": "555-5555" } ] }
A ticket that has a scope that is too limited is problematic because it can't be tested on its own. A ticket that is too big is also problematic. Tickets should be completable in a single sprint. How long a spring is, depends on your team, but is normally one or two weeks. At creation time, it is always hard to estimate the effort level of a ticket, which is why many teams have team meetings to estimate the level of effort (or "story points" in Agile lingo). These meetings depend on tickets already being created, which means that someone must make an initial decision regarding how big each ticket should be.
Developers should feel empowered to take any ticket assigned to them, and if they feel it's too big, break it down into more manageable tickets. However, if we're creating the tickets, we should take care to avoid creating tickets that are too big to start with.
- What information do we need to provide for each ticket to ensure it is implementable and testable?
- Does any of the tickets need to be broken up to make it completable in a single sprint?
From Bug Reports to Tickets
Sometimes tickets are not created in the process of adding new features to a piece of software. Sometimes tickets are created through another path, via bug reports. Bug reports are reactive, as they signal a condition that the development team had not detected during the normal development process. Bug reports can come at different times during the development process, as they are discovered at unpredictable times. For example, they can be detected by the Q&A team when they are testing a feature before launching it. Bugs can also be detected by the end users once an application has already been launched into production. Furthermore, bugs are sometimes detected by developers, as they're working on unrelated features.
In Chapter 5 and Chapter 6 we go into detail on how to write good unit and integration tests to limit the number of bugs that make it to the Q&A team or our users, but regardless of how good our unit tests are, we must be able to receive, triage, and act upon bug reports. From a high enough viewpoint, bug reports are just tickets that must be prioritized and addressed like any other ticket. Depending on the severity of the bug, the bug might upend our previous priorities and demand immediate action.
Depending on the mechanisms we have for reporting bug reports, tickets might be separate from bug reports.
Given the potentially disruptive effects of bug reports, we must have guidelines and mechanisms to ensure the tickets we generate from bug reports are of high quality. A high-quality bug report will serve to main purposes:
- Enable the developer to reproduce the issue.
- Help establish the severity of the bug, triage it, and prioritize it properly.
As Senior Developers, it is part of our responsibility to ensure that we get enough information to fulfill these two requirements.
A ticket to address a bug report should have at a minimum the following information:
- Title and Summary
- Expected vs. Actual result
- Steps to Reproduce
- Environment
- Reference information
- Logs, screenshots, URLs, etc.
- Severity, impact, and priority
Some of these pieces of data will come from the bug reports directly, while others might have to be compiled externally. For example, we might have to retrieve relevant logs and attach them to the ticket. If we have multiple multiple bug reports, it might be necessary to correlate and condense them to determine the severity and impact of a particular bug. A single ticket should be able to be linked to one or more related bug reports. This is easily supported by most ticket/issue tracking software.
In cases where bug reports are separate from tickets, it's important to always keep a link to be able to reference the original bug report (or bug reports). Maintaining this link will help developers reference the source of the bug in case there are any questions.
In the same vein, some of the information might have to be edited to adapt to an actionable ticket, for example by making the title and summary concise and descriptive.
We must make it easy for our users to generate high-quality bug reports. Making it easy for our users, will make it easier for us to manage these bug reports and promptly address any underlying issue.
For example, we create templates in our issue or ticket tracking software to ensure all of the proper fields are populated.
Specific templates can be developed for different components or services, to ensure we capture the relevant information.
This reduces the need to go back and ask for more data from the bug reporter.
If at all possible, embedding the bug report functionality as part of the application itself makes it easier for users to report their bugs, while at the same time having the opportunity to collect (with the consent of the user) diagnostic information and logs that will help to debug the issue.
Depending on the application, it is possible to create a unique identification number that allows us to track a transaction throughout our systems. This unique transaction ID can then be correlated to log messages. Capturing this ID as part of the bug report makes it easy for a developer to access the relevant logs for a bug report.
This ID can be exposed to the user so that they can reference it if they have to create a bug report or contact user support.
As part of facilitating the creation of high-quality bug reports, we must keep in mind what are the typical problems we encounter with bug reports:
- Vague wording
- Lack of steps to reproduce
- No expected outcome
- Ambiguous actual outcome
- Missing attachments
- Misleading information
Regardless of how well we craft the bug reporting mechanism,
there will be times when we will have to deal with problematic bug reports.
Normally the biggest problem is the lack of instructions to replicate the bug.
In most cases, the first step is to reach back to the bug reporter and get more clarifying information.
Many bug reports can be clarified with a little effort and provide a good experience to our users.
Keep in mind that many users might use a different vocabulary than what developers might use, and asking for clarification should be done in an open-minded way.
Sometimes it might not be possible to get enough information to create an actionable ticket,
and in such cases, it's reasonable to close with "Can't reproduce" or the equivalent status in your issue tracking software.
When dealing with bug reports, especially ones coming from users, remember that there is normally some level of frustration from the user.
We must be objective and fair.
Always keep in mind the ultimate goal is to have better software.
- What information do we need to have useful bug reports?
- How are we going to gather this information?
Prioritizing Bug Reports
Once we have created a high-quality actionable ticket based on a bug report, we have to determine how to act on it.
Should a developer drop everything they're doing and fix it?
Should it be an all-hands-on-deck trying to fix it? Even other teams?
Can it just go into our backlog for the next sprint?
As a Senior Developer, you should have the context to answer this. However, we can different frameworks to have a more structured and objective mechanism.
For example, a probability impact risk matrix can be used as a reference to prioritize a bug ticket. Using such a matrix, we consider how many users are potentially affected, and how severe the impact is for those that are affected.
If we had five priorities ("Highest", "High", "Medium", "Low", and "Lowest") we could create a risk matrix to determine the priority for a particular bug.
| Negligible | Minor | Moderate | Significant | Severe | |
|---|---|---|---|---|---|
| Very Likely | Low | Medium | High | Highest | Highest |
| Likely | Very Low | Low | Medium | High | Highest |
| Probable | Very Low | Low | Medium | High | High |
| Unlikely | Very Low | Low | Low | Medium | High |
| Very Unlikely | Very Low | Very Low | Low | Medium | Medium |
A word of caution with the risk matrix: Most people tend to classify every bug at either high or low extreme, reducing the usefulness of the matrix.
There are other mechanisms that can help you prioritize bug reports:
- Data Loss: Any bug that causes data loss will have the highest priority.
- SLO impact: If you have well-established SLOs (Service Level Objects), you can prioritize a bug depending on the impact it has on the SLO and Error Budget. We into detail about SLOs and Error budgets in Chapter 10.
Tools Referenced
- PlantUML Open-source tool allowing users to create diagrams from a plain text language. PlantUML makes it very easy to generate sequence diagrams, as well as a plethora of other diagram types. Many of the diagrams in this book are rendered using PlantUML. PlantUML can be run locally or you can use the hosted service.