Senior Developer in 24 hours
In the realm of technology, the path to becoming a senior software developer is a journey marked by continuous learning, problem-solving prowess, and a relentless pursuit of excellence. This book serves as your compass in navigating the intricate landscapes of software development, offering a comprehensive guide to acquiring the skills that elevate you to the coveted position of a senior developer.
Embark on a transformative odyssey as you delve into the nuances of the software developement lifecycle, learn to decipher complex problems, and cultivate the art of collaboration within development teams. With real-world examples and hands-on exercises, this book not only equips you with the technical acumen required for senior roles but also delves into the soft skills and leadership qualities that distinguish exceptional developers. Whether you're a budding programmer seeking to ascend the ranks or an experienced developer aiming to stay at the top of your game, this guide is your roadmap to mastering the skill set of arguably the most trascendental occupation of the information age: software developer.
What Makes a Senior Software Developer?
In the world of software development, a Senior Software Developer is the core of the team. The people who can truly fill the role of a Senior Software Developer are few, and as such, in extremely high demand. This book is an attempt to condense the skills and traits required to make the jump from a Junior Software Developer to a Senior Software Developer. But the first step is to define what we mean by Senior Software Developer and Junior Software Developer.
Junior Software Developers are normally entry-level software developers who assist the development team with all aspects of the software development lifecycle. However, their primary role is to write code and fix bugs, normally based on well-defined tickets and bug reports. The day-to-day of a Junior Software Developer normally consists of picking up (or being assigned) a particular bug, working on it until completion, and then picking up the next bug. Besides tackling tickets, Junior Developers will become intimate with parts of the codebase, making their input valuable in other areas of the design and development process.
Senior Software Developers will spend a lot of their time writing code and closing tickets, but the value they provide goes far beyond. Senior Developers are a force multiplier that will enable Junior Developers to operate at their full capacity. In this book we are going to focus on how we can become enable the creation of better software, a skill above just writing better code.
What a Senior Software Developer is not?
Some characteristics and traits are associated with a Senior Software Developer but do not contribute directly to the effectiveness of a Senior Software Developer. For example:
Years of experience: Many times organizations, and especially Human Resource departments and recruiters, equate a lengthy tenure with a Senior position. While having multiple years of experience is typical for Senior Developers, just having those years does not provide on its own the skills that a Senior Software Developer should bring to the table.
Writing code the fastest: A Senior Developer should be able to solve problems faster, but that doesn't necessarily mean that they write raw code faster. Senior Developers are better at understanding what code should be written, what code or libraries can be reused, and what code shouldn't be written in the first place.
Intimate knowledge of the company's codebase: While many Senior Developers will have intimate knowledge of the codebase that they are working on, it is not in itself a hard requirement. One of the attributes that Senior Developers bring is the ability to quickly learn their way around a new codebase.
Junior Software Developer vs. Senior Software Developer
To plot our path from Junior Software Developer to Senior Software Developer, it's vital to understand the difference between the two. Or at the very least understand the basic role of Junior Software Developers.
Junior Developers follow a very simple workflow, where they pick up a ticket, work on the ticket until it's done, submmit their changes, and then pick up a new ticket to start the process all over again. Senior Software Developers will also work on tickets but also need to keep a more holistic view of the system. This holistic view includes:
- Gathering and grooming requirements
- Ensuring functional and non-functional requirements are met
- Having an opinionated take on whether code should be written, or if alternative solutions should be used
- Understanding the end-to-end Software Development Lifecycle (SDLC)
We'll go into a lot more detail in the next chapters, but we can summarize the main differences between Junior and Senior Developers in the following table:
| Junior | Senior |
|---|---|
| Focused on tickets | Holistic view of application |
| Functional Requirements | Functional and non Functional Requirements |
| Writes code | Should we even write this code? Can we remove this code? |
| Limited view of SDLC | End-to-end view of SDLC |
Architect vs. Senior Software Developer
Another persona that is often seen in the higher ranks of software development organizations is the Architect. Normally prefaced by even more enthusiastic terms such as "Enterprise" or "Solution", the Software Architect is another potential career development path for Software Developers.
Architects normally work at the organizational level, keeping a holistic view of the system, rather than focusing on an individual component level. Sr. Software Developers will focus more on their component, while also keeping an eye out to understand how it fits within the bigger picture.
Architects work mostly at the development organization level, while Senior Software Engineers work more at the team level. This means that in an organization, you will find many more Senior Software Engineers with only a few Architects.
The deliverables produced by Architects are more theoretical, think UML diagrams, design documentation, standards, and occasionally some proof of concept code. On the other hand, Senior Software Engineers will produce a lot more code, with some supporting documentation (design diagrams, standards, etc.).
It is worth noting that in other cases Enterprise Architects or Solution Architects are part of the sales organization, and as such their job is more aligned with architecting "Sales Proposals" or "RFP (Request For Proposals) Responses" rather than architecting the actual system that will be built.
Both the Software Architect and the Senior Software Developer must be thought leaders in the organization and must collaborate to bring about the vision of the organization. An architect who proposes a design that the software developer can't deliver is not contributing to the fulfillment of this vision. In the same manner, a software developer who works without understanding how their components fit in the overall organization is not contributing value to the organization.
We can summarize the main differences between an Enterprise Architect and a Senior Developer in the following table:
| Architect | Senior Developer |
|---|---|
| Holistic view of system | Deep knowledge of a component |
| Concerned about non Functional Requirements | Concerned about Functional and non Functional Requirements |
| Organization level | Team level |
Backend vs Front-end Development
It is also important to note that for the scope of this book, we're going to be focusing on backend development. While some of the topics covered in the book might apply to front-end development, the ecosystem is different enough that to achieve proficiency in either field, true specialization is required.
About the Author

Andrés Olarte has tackled multiple changes in IT, from working as a systems adminstrator, to Java Development of enterprise applications, to working as a consultant helping customer develop cloud native application.
Currently, Andrés works as a Strategic Cloud Engineer for the professional services organization at Google Cloud.
Andrés loves learning new things and sharing the knowledge. He has spoken at multiple events, such as "Chicago Java Users Group".
Andrés writes at his personal blog The Java Process.
About this Book
The book is structured around 24 chapters. Each chapter covers one topic in depth, and should be readable in one hour or less. Depending on your previously experience and knowledge, you might want to branch out and seek more information on any particular topic. Each chapter will provide a concise list of the tools that are referenced.
As part of the process of condensing the information and techniques for this book, a series of videos discussing the topics were created. The videos will listed within each chapter.
Who is the target audience of this book?
This book is geared towards "entry-level" or "junior" software developers, that want to grow their careers. If you already have the basic knowledge of how to write code, the material here will help you gain the skills to move up in your career.
In this book, we skip over a lot of basic topics, to focus on the areas where a Senior Software Developer can provide value. In this book, we are not trying to replace the myriad of coding boot camps or beginner tutorials that are out there, but rather provide a structured set of next steps to advance in your career. We also skip a formal review of Computer Science focused topics. There are plenty of sources for Computer Science theory, including preparation for CS-heavy interview questions that are popular in some companies.
If you are already a Senior Software Developer, you might find the material useful as a reference, as we provide opinionated solutions to common problems that are found in the field.
Decisions, decisions, decisions
One of the main roles of a Senior Software Developer is to make decisions.
When we hear "decision maker", we normally think of a high level executive,
however software developers make tens if not hundreds of decisions every day.
Some of these decisions might be small, but some might be very impactful.
A bad decision when choosing a timeout could cause a mission critical system to fail,
and a bad decision regarding our concurrency logic could limit how much the operations of the business can scale.
In a large business, one of those bad decisions could have a price tag of thousands or millions of dollars.
For example, in 2012, Knight Capital Americas LLC,
a global financial services firm engaging in market making, experienced a bug.
This bug caused a significant error in the operation of its automated routing system for equity orders, known as
SMARS1. Due to a misconfigured feature flag, SMARS routed millions of orders into the market over a 45-minute period.
The incident cause a loss of $450 million. 2
The decisions a software developer makes are very important, and we always must take into consideration three aspects:
- The problem at hand
- The technologies available
- The context (from a technical perspective, but also from an organizational perspective)
Some of the decisions we can take on our own, for example: "How should we name a variable?" Other decisions will require consulting other teammates or external stakeholders. For larger decisions that impact the overal architecture of a solution, we might even have to negotiate to reach a concensus. The more ramifications a decision has outside our application, the more we'll have to involve other parties.
Whatever the decision, it's important to always keep in mind the context in which we're taking the decision. Many of the decisions we discuss here, might have already be defined in a large organization, and if we need to go against those standards, we need to have a very good reason to justify it.
Which brings us to another point to keep in mind: pick your battles. When trying to defend our point of view against someone with an oposing view, it's important to weigh if there's value in prevailing, while potentially spending a lot of time or burning political capital. Sometimes it's better to concede against a differing opinion, when there's marginal to choosing either alternative.
We can start by clasifying decisions into Type 1, which are not easy to reverse or non-reversable at all; or Type 2 decision which are easy to reverse if needed.
In an Amazon shareholder letter, CEO Jeff Bezos explained how we need to fight the tendency to apply apply a heavy decision making to decision that don't merit that much thought:
Some decisions are consequential and irreversible or nearly irreversible – one-way doors – and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation. If you walk through and don’t like what you see on the other side, you can’t get back to where you were before. We can call these Type 1 decisions. But most decisions aren’t like that – they are changeable, reversible – they’re two-way doors. If you’ve made a suboptimal Type 2 decision, you don’t have to live with the consequences for that long. You can reopen the door and go back through. Type 2 decisions can and should be made quickly by high judgment individuals or small groups.
As organizations get larger, there seems to be a tendency to use the heavy-weight Type 1 decision-making process on most decisions, including many Type 2 decisions. The end result of this is slowness, unthoughtful risk aversion, failure to experiment sufficiently, and consequently diminished invention. We’ll have to figure out how to fight that tendency.
-- Jeff Bezos 3
With that said, it's important to understand in which decisions, we must apply a heavy and involved decision making process. Discussions can always be valuable to have, but must always be respectful.
We need to be ready to defend our decisions, so we need to think about the different trade-offs, as well as the context in which we're taking these decisions.
Throughout the book, key decision points will be higlighted in clearly marked boxes:
Tech Stacks
Most of this book covers material that is independent of a particular tech stack. However, when it comes to practical examples, we focus on three tech stacks that are popular for backend development:
Other languages will be mentioned if they are relevant to a particular topic.
Introduction Video
1 "ORDER INSTITUTING ADMINISTRATIVE AND CEASE-AND-DESIST PROCEEDINGS,". Securities and Exchange Commission, 2013, https://www.sec.gov/files/litigation/admin/2013/34-70694.pdf
2 Popper, N. (2012, August 2). Knight Capital says trading glitch cost it $440 million. The New York Times. https://archive.nytimes.com/dealbook.nytimes.com/2012/08/02/knight-capital-says-trading-mishap-cost-it-440-million/
3 "LETTER TO SHAREHOLDERS,". Jeffrey P. Bezos, 2015, https://www.sec.gov/Archives/edgar/data/1018724/000119312516530910/d168744dex991.htm
From User Requirements to Actionable Tickets
Why is This Important?
When people think of software developers, they think of someone who writes code all day long. While writing code is one of the main tasks of a developer, many developers spend lots of time on other activities. These activities enable us to get to the point where we can write the code, or make sure that the code that we write is useful. In most teams, it is up to the Senior Developers to guide these activities to ensure that all of the developers have clear and actionable tickets.
In this chapter, we cover how can go from vague or abstract requirements to actionable tickets, by breaking down the process into several stages.
The Work Cycle of a Developer
As we mentioned in the introduction most software developers are used to a fairly simple work cycle in their day-to-day:

However, this assumes that the tickets have already been created. The person in charge of creating the tickets will vary from team to team. But in most teams, the Sr. Developers will at least have an active role in defining the scope of these tickets, and how large chunks of work will be divided into digestible tickets. At most, the Sr. Developer will have an active role in identifying and analyzing the user requirements. In this chapter, we will cover how we can create better tickets starting from raw user requirements.
Using a Structured Approach
Going from user requirements to actionable tickets can seem like a daunting endeavor. And like any big endeavor, it helps to break down the process into a structured approach that we can follow step by step.
The proposed approach can be seen in the diagram below:

Some of these terms can have different meanings depending on the context, so we'll define a common language that we'll be using throughout the book. Your organization or team might use slightly different meanings, so it's important to take the context into account.
- User Requirements: requirements set by the end user.
- User Journey: a set of steps a user takes to accomplish a goal.
- Epic: a large body of work with a unifying theme.
- Ticket: the smallest unit of work a developer undertakes.
Keep in mind that going from user requirements to actionable tickets is more an art than a science. The process also requires negotiation to determine what is technically feasible and valuable based on cost/benefit analysis. Not every feature request can be delivered within a reasonable timeframe or with limited resources. A Senior Developer must be willing to listen to other stakeholders and negotiate a lot of ambiguity to distill the high-quality tickets on top of which successful software is built.
User Requirements
User requirements are, as the name implies, the requirements set by the end user. Alternatively, they can be the requirements set by someone else on behalf of the user, sometimes with limited input from the user.
In general, who provides the user requirements?
- Users
- Product Owners
- Business Analysts
- Q/A Team
In cases where the user requirements are provided by someone other than the actual end user, how do we gather data to ensure we're really representing what the user wants? Many techniques exist to accomplish this goal:
- Surveys
- Interviews or focus groups with users
- User Observation
- Usage Data Collection
Other times, the features ideated in brainstorming sessions, where subject matter experts put together their collective creativity to come up with the great next innovation.
Sometimes the requirements we receive as a Software Developer are very detailed. Other times we will get very abstract or vague requirements, that read more like a wishlist.
In the worst case, we will receive non-actionable user requirements. For example:
- We want to improve the application
- We want our users to be more engaged
- We want our applications to be easier to use
In cases where we get these non-actionable requirements, we need to push back and either get more information or discard requirements that won't be translatable into any tangible work. As developers, we use our code to achieve goals, but our code can't bridge gaps in the vision of an organization. These user requirements must be identified early in the process and sent back or discarded.
User Journeys
Mapping user journeys is best done in sessions with representatives from the different areas that are affected by a particular application or piece of functionality.
This can be done in a whiteboard, to allow a more inclusive environment and provide a more holistic view of the different requirements and how they relate to each other.
In these sessions, our objective is to document three critical pieces of information for each requirement:
- Who? Who is the user that is acting?
- What? What is the user trying to accomplish?
- How? How is the user going to achieve their goal?
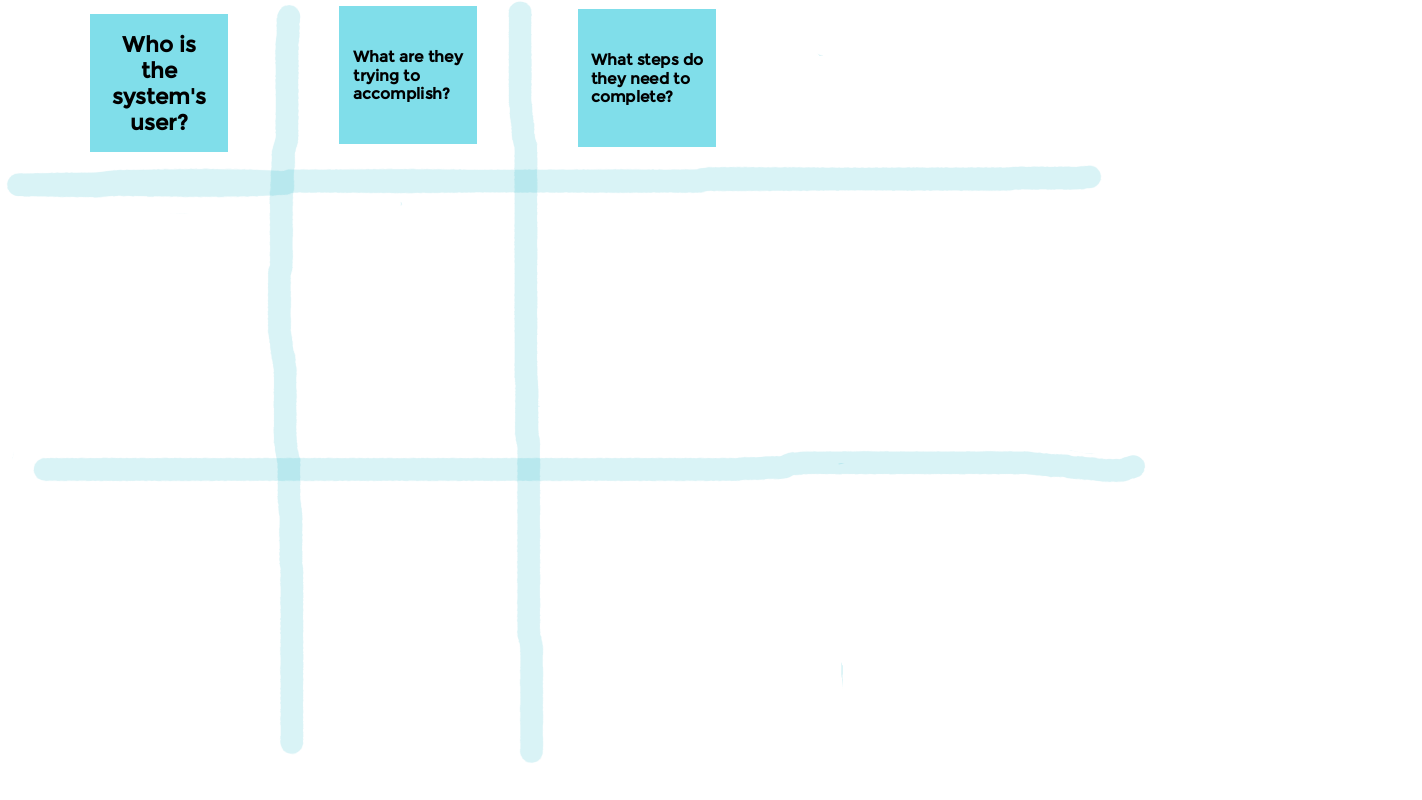
Brainstorming will normally result in a series of users, goals, and steps. At the brainstorming phase, it's important to try to capture all of the proposed ideas, they can be refined at a later stage.
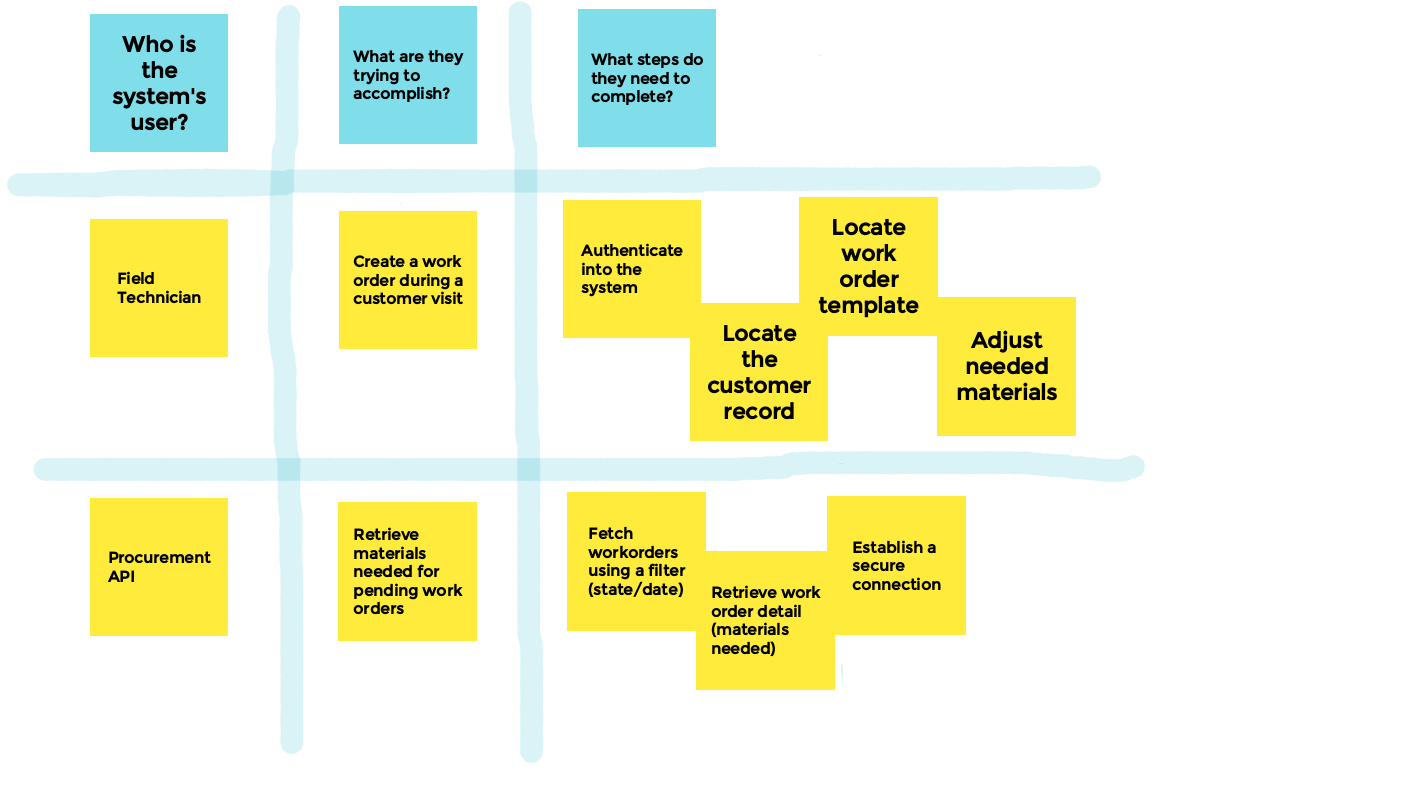
Once there are enough users, goals, and steps on the board, the next step is to organize them. Group together the ones that share common themes, and combine redundant ones.
Once the users, goals, and sets of steps are organized, and depending on the number of ideas up on the board, this might be a good time to take some time and vote for the ones that the team feels are most valuable.
If there's a feeling that ideas are still not properly represented on the board, you can repeat the brainstorming process until the group is satisfied.
Documenting User Journeys
Once some level of consensus has been achieved, it's important to document the user journeys in a non-ambiguous manner. Remember that one of the critical objectives of a user journey mapping session is to create a shared understanding of the user requirements. Even if there are detractors regarding a particular user journey, it's valuable to have a shared understanding. Objections can be better addressed when the specifics are clear to all parties involved.
Both activity diagrams and sequence diagrams can be used to show actions and relationships.
Activity diagrams show the order or flow of operations in a system, while a sequence diagram shows how objects collaborate and focuses on the order or time in which they happen. Generally, sequence diagrams can better illustrate complicated use cases where asynchronous operations take place.
Here we see an example sequence diagram:

Sequence diagrams can be stored as code. Storing diagrams as code makes it easier to share across the team and iterate. Someone with experience can quickly edit sequence diagrams on the fly, helping visualize the flow in real-time as a group of subject matter experts watches.
@startuml
actor "Actor" as Act1
participant "Component" as App
Act1 -> App : Message
App --> Act1: Response
Act1 ->> App : Async Message
App --> Act1: Async Response
loop while done!=true
Act1 -> App: Message
App --> Act1: Response
end
@enduml
Example sequence diagram:

Remember each user journey should tell us:
- Who is the user?
- What are they trying to accomplish?
- What steps do they need to complete?
At this point, you might have a lot of User Journeys. The next step would be to improve the focus by ranking them based on their relative importance to the organization. The ranking can be done by having the SMEs vote on their priorities, or maybe there's a product owner who has the responsibility to set priorities.
Creating Epics
Epics are a large body of work with a unifying theme. In this section, we will focus on epics that are derived from the functionality defined in user journeys, to continue the series of steps to go from user requirements to actionable tickets.
However, in the real world, epics might be defined differently and have different themes. For example, could be an Epic to encompass the work needed to make a release on a particular date, or an epic to remediate a shortcoming in an existing piece of software.
When talking about epics, we have to understand the context in which we are going to be developing the functionality described in an epic.
For example, is our software greenfield or brownfield?
- Greenfield: A project that starts from scratch and is not constrained by existing infrastructure or the need to integrate with legacy systems.
- Brownfield: Work on an existing application, or work on a new application that is severely constrained by how it has to integrate with legacy systems or infrastructure.
Is the software in active development, or just under maintenance?
- Active Development: A project where we're adding new features is considered in active development. These new features can be added either as part of the initial development or subsequent enhancements added after going into production. It is expected that new features will provide new value.
- Maintenance: A project where no new features are being added is considered to be in maintenance. Changes to software under maintenance are limited to bug fixes, security updates, changes to adhere to changing regulations, or the minimum changes needed to keep up with changing upstream or downstream dependencies. No new value is expected to be gained from the maintenance, but rather just a need to remain operational.
Based on the work we did documenting user journeys, we can use these user journeys as the basis for our epics. We can start creating one epic per user journey. Normally an epic will have enough scope to showcase a discreet piece of functionality, more than enough to create a sizeable number of tickets. As we work on planning or creating the tickets, it will become evident that there is overlap across some of the epics. It's important to identify these overlaps and extract them into standalone epics (or tickets as part of existing epics) The disconnect between how we construct user journeys, and how the software has to be built will always result in dependencies we have to manage.
For example, if we had an epic to create a new work order, they might look something like this:
- Epic: A Field Tech needs to create a new work order
- Ticket: Create authentication endpoint
- Ticket: Create an endpoint to search for customers
- Ticket: Create an endpoint to search work order templates
- Ticket: Create an endpoint to adjust materials
- Epic: A Customer Service Rep needs to create an appointment
- Ticket: Create an authentication endpoint
- Ticket: Create an endpoint to search for field techs
- Ticket: Create an endpoint to create an appointment record
It is evident that the first ticket "Create authentication endpoint" is a cross-cutting concern that both epics depend on, but is not limited the either one. And most importantly, we don't want to end up with two different authentication endpoints!
A holistic view is critical to effectively slice up the work into epics and tickets.
If we rearrange the epics and tickets, we can have better-defined epics:
- Epic: A Field Tech needs to create a new work order
Ticket: Create authentication endpoint- Ticket: Create an endpoint to search for customers
- Ticket: Create an endpoint to search work order templates
- Ticket: Create an endpoint to adjust materials
- Epic: A Customer Service Rep needs to create an appointment
Ticket: Create an authentication endpoint- Ticket: Create an endpoint to search for field techs
- Ticket: Create an endpoint to create an appointment record
- Epic: Provide an authentication mechanism
- Ticket: Create an authentication endpoint
Furthermore, we can then add more detail to the epics as we start thinking about the implementation details that might not be fully covered in our user journeys. For example, this might be a good time to add a ticket to manage the users:
- Epic: Provide an authentication mechanism
- Ticket: Create an authentication endpoint
- Ticket: Create user management functionality
There is a dependence on the authentication mechanism. Adjusting for these dependencies is an ever-present challenge. Rather than trying to perfectly align everything in a Gantt Chart to deal with dependencies, we provide a more agile approach in Chapter 4.
- Which epics do we need to create for each Critical User Journeys?
- Do any cross cutting epics need to be created?
- Which tickets will we create for each epic?
Creating Tickets
In the previous section, we have already started talking about creating tickets, in particular, what tickets to create. So in this section, we're going to focus on how the tickets should be created.
In general, a good ticket should have the following attributes:
- Define concrete functionality that can be tested
- Have a completion criteria
- Achievable in a single sprint
The ticket should have enough information describing a concrete piece of functionality. At this stage, the ambiguous and vague ideas that were brainstormed during the user journey brainstorming have to be fleshed out into detailed requirements that can be implemented with code.
As part of the definition of this concrete functionality, we can include:
- Any specifications that must be implemented, for example, API specifications already agreed upon.
- Sample scenarios or test cases that the functionality must be able to pass. These can be used with Behaviour Driven Development.
- Sample data that the functionality will process.
- Detailed diagrams or pseudo-code
- Detailed explanation of the desired functionality
The scope of a single ticket should be testable. At the early stages of development, the testing might be limited to unit testing, as we might depend on external components that are not yet available. For some of the very simple tickets, "testable" might mean something very simple. For example visually verifying that a label has been updated to fix a typo, or that a new button is visible even though there is no logic is attached to the button. To ensure that the scope of the ticket is enough to stand on its own, there should be concrete completion criteria.
To define an actionable completion criteria, you can reference back to the actions that were defined as part of the user journey.
For example, a good completion criteria would look like this:
- Must be accessible at
/customersas aGEToperation. - Must take an arbitrary string as a parameter
q. - Must return any customer records that match the text from the query.
- Matches against all fields in the customer record.
- If no matches, return an empty set.
- Response data format:
{"results": [...]}
Putting it all together an actionable ticket would look like this:
Title: Create endpoint to search for customers
Description:
Create
GETendpoint at/customersthat:
- Is accessible by field techs
- Takes an arbitrary string as parameter "
q"- Matches the string against all fields in customer records
- Returns the list of matching records
- If no matches, return an empty set
- Response data format:
{ "results": [ { "customer_id": "xxx", "first_name": "John", "last_name": "Doe", "email": "john@test.com", "phone": "555-5555" } ] }
A ticket that has a scope that is too limited is problematic because it can't be tested on its own. A ticket that is too big is also problematic. Tickets should be completable in a single sprint. How long a spring is, depends on your team, but is normally one or two weeks. At creation time, it is always hard to estimate the effort level of a ticket, which is why many teams have team meetings to estimate the level of effort (or "story points" in Agile lingo). These meetings depend on tickets already being created, which means that someone must make an initial decision regarding how big each ticket should be.
Developers should feel empowered to take any ticket assigned to them, and if they feel it's too big, break it down into more manageable tickets. However, if we're creating the tickets, we should take care to avoid creating tickets that are too big to start with.
- What information do we need to provide for each ticket to ensure it is implementable and testable?
- Does any of the tickets need to be broken up to make it completable in a single sprint?
From Bug Reports to Tickets
Sometimes tickets are not created in the process of adding new features to a piece of software. Sometimes tickets are created through another path, via bug reports. Bug reports are reactive, as they signal a condition that the development team had not detected during the normal development process. Bug reports can come at different times during the development process, as they are discovered at unpredictable times. For example, they can be detected by the Q&A team when they are testing a feature before launching it. Bugs can also be detected by the end users once an application has already been launched into production. Furthermore, bugs are sometimes detected by developers, as they're working on unrelated features.
In Chapter 5 and Chapter 6 we go into detail on how to write good unit and integration tests to limit the number of bugs that make it to the Q&A team or our users, but regardless of how good our unit tests are, we must be able to receive, triage, and act upon bug reports. From a high enough viewpoint, bug reports are just tickets that must be prioritized and addressed like any other ticket. Depending on the severity of the bug, the bug might upend our previous priorities and demand immediate action.
Depending on the mechanisms we have for reporting bug reports, tickets might be separate from bug reports.
Given the potentially disruptive effects of bug reports, we must have guidelines and mechanisms to ensure the tickets we generate from bug reports are of high quality. A high-quality bug report will serve to main purposes:
- Enable the developer to reproduce the issue.
- Help establish the severity of the bug, triage it, and prioritize it properly.
As Senior Developers, it is part of our responsibility to ensure that we get enough information to fulfill these two requirements.
A ticket to address a bug report should have at a minimum the following information:
- Title and Summary
- Expected vs. Actual result
- Steps to Reproduce
- Environment
- Reference information
- Logs, screenshots, URLs, etc.
- Severity, impact, and priority
Some of these pieces of data will come from the bug reports directly, while others might have to be compiled externally. For example, we might have to retrieve relevant logs and attach them to the ticket. If we have multiple multiple bug reports, it might be necessary to correlate and condense them to determine the severity and impact of a particular bug. A single ticket should be able to be linked to one or more related bug reports. This is easily supported by most ticket/issue tracking software.
In cases where bug reports are separate from tickets, it's important to always keep a link to be able to reference the original bug report (or bug reports). Maintaining this link will help developers reference the source of the bug in case there are any questions.
In the same vein, some of the information might have to be edited to adapt to an actionable ticket, for example by making the title and summary concise and descriptive.
We must make it easy for our users to generate high-quality bug reports. Making it easy for our users, will make it easier for us to manage these bug reports and promptly address any underlying issue.
For example, we create templates in our issue or ticket tracking software to ensure all of the proper fields are populated.
Specific templates can be developed for different components or services, to ensure we capture the relevant information.
This reduces the need to go back and ask for more data from the bug reporter.
If at all possible, embedding the bug report functionality as part of the application itself makes it easier for users to report their bugs, while at the same time having the opportunity to collect (with the consent of the user) diagnostic information and logs that will help to debug the issue.
Depending on the application, it is possible to create a unique identification number that allows us to track a transaction throughout our systems. This unique transaction ID can then be correlated to log messages. Capturing this ID as part of the bug report makes it easy for a developer to access the relevant logs for a bug report.
This ID can be exposed to the user so that they can reference it if they have to create a bug report or contact user support.
As part of facilitating the creation of high-quality bug reports, we must keep in mind what are the typical problems we encounter with bug reports:
- Vague wording
- Lack of steps to reproduce
- No expected outcome
- Ambiguous actual outcome
- Missing attachments
- Misleading information
Regardless of how well we craft the bug reporting mechanism,
there will be times when we will have to deal with problematic bug reports.
Normally the biggest problem is the lack of instructions to replicate the bug.
In most cases, the first step is to reach back to the bug reporter and get more clarifying information.
Many bug reports can be clarified with a little effort and provide a good experience to our users.
Keep in mind that many users might use a different vocabulary than what developers might use, and asking for clarification should be done in an open-minded way.
Sometimes it might not be possible to get enough information to create an actionable ticket,
and in such cases, it's reasonable to close with "Can't reproduce" or the equivalent status in your issue tracking software.
When dealing with bug reports, especially ones coming from users, remember that there is normally some level of frustration from the user.
We must be objective and fair.
Always keep in mind the ultimate goal is to have better software.
- What information do we need to have useful bug reports?
- How are we going to gather this information?
Prioritizing Bug Reports
Once we have created a high-quality actionable ticket based on a bug report, we have to determine how to act on it.
Should a developer drop everything they're doing and fix it?
Should it be an all-hands-on-deck trying to fix it? Even other teams?
Can it just go into our backlog for the next sprint?
As a Senior Developer, you should have the context to answer this. However, we can different frameworks to have a more structured and objective mechanism.
For example, a probability impact risk matrix can be used as a reference to prioritize a bug ticket. Using such a matrix, we consider how many users are potentially affected, and how severe the impact is for those that are affected.
If we had five priorities ("Highest", "High", "Medium", "Low", and "Lowest") we could create a risk matrix to determine the priority for a particular bug.
| Negligible | Minor | Moderate | Significant | Severe | |
|---|---|---|---|---|---|
| Very Likely | Low | Medium | High | Highest | Highest |
| Likely | Very Low | Low | Medium | High | Highest |
| Probable | Very Low | Low | Medium | High | High |
| Unlikely | Very Low | Low | Low | Medium | High |
| Very Unlikely | Very Low | Very Low | Low | Medium | Medium |
A word of caution with the risk matrix: Most people tend to classify every bug at either high or low extreme, reducing the usefulness of the matrix.
There are other mechanisms that can help you prioritize bug reports:
- Data Loss: Any bug that causes data loss will have the highest priority.
- SLO impact: If you have well-established SLOs (Service Level Objects), you can prioritize a bug depending on the impact it has on the SLO and Error Budget. We into detail about SLOs and Error budgets in Chapter 10.
Tools Referenced
- PlantUML Open-source tool allowing users to create diagrams from a plain text language. PlantUML makes it very easy to generate sequence diagrams, as well as a plethora of other diagram types. Many of the diagrams in this book are rendered using PlantUML. PlantUML can be run locally or you can use the hosted service.
Videos
Identifying and Analyzing User Requirements
Identifying and Analyzing User Requirements, continued
Foundation of a Software Application
Why is This Important?
We don't always get the privilege to build an application from scratch. But when we do, creating a solid foundation is one of the most important tasks to ensure the success of the project. In this section, we go into details
Decisions, Decisions
As a Sr. Software Developer, we have to constantly make decisions, from little details to very big transcendental choices that will have ramifications for years to come.
In the introduction of the book, we discussed how some of the decisions we have to make can have transcendental implications for an organization. With this in mind, we can start thinking about the specific decisions we have to make to get a software project started from scratch. In the context of this book, this software project can take different shapes. It can be a back-end service that our organization will host, a software product that our customers will run, a shared component meant to be consumed by other projects, etc.
These basic decisions include:
- Programming language
- Language version to target
- Frameworks to adopt
- Libraries to use
- Where to store the code
- Number of code repositories and their structure
- The structure of the code
A lot of these are already defined in large organizations, so we always need to take that context into account. Nonetheless, we're going to go through the different decisions in detail in the following sections.
Choosing the Language and Language Version
When faced with a new project, many developers want to dive right in and start writing code.
But before we print that first Hello World!, we need to know which programming language we're going to use.
Many times this will be obvious, but we're still going to explore the process through which we arrive at a decision.
To choose the language and the specific language version, it's important to understand the constraints under which we're operating.
- What language or languages does our team know?
- What languages does our organization support?
- If our code is going to be shipped to customers, what languages do our customers favor?
- Do we have required language-specific dependencies?
Languages Within the Team
Most teams are assembled around a particular skill set, with language familiarity being one of the primary skills considered. Some team members will be motivated to try and learn new languages, while other team members would rather specialize in one primary language and would rather not fork to learn a new language.
Understanding the skillset (and willingness to learn new ones) of our team is the first step to making the decision regarding which language to use.
With that said, some shifts are relatively minor and might be more feasible, in particular when we're shifting to a related language.
The smallest shift is when we upgrade the major version of our language. For example, upgrading from Python 2 to Python 3 is a small but significant change. The syntax is similar, but not exactly equal, and many of the third-party libraries are not compatible from 2 to 3.
A bigger shift is when we move to a related language in the same family. For example, a Java team could make a jump Kotlin with relatively little trouble. Kotlin is heavily influenced by Java, runs on the same JVM (Java Virtual Machine), can interoperate with Java, has the same threading model, uses the same dependency management mechanism, etc. Both languages share the same programming paradigm and ecosystem, and their syntax is not that dissimilar.
Similarly, moving from JavaScript to TypeScript is a much smaller shift since they share most of the syntax and the same programming paradigm and ecosystem.
Bigger jumps, for example from Java to JavaScript or TypeScript, need to be very well supported. These changes must be very well supported, since they require not only learning a new syntax, but also a new ecosystem, and potentially a new programming paradigm.
Languages Within the Organization
The popularization of container-based workflows (Docker containers in particular) has opened up the gates for organizations to be able to support a lot more different languages. Suddenly we can support more runtimes, more heterogeneous build pipelines, etc. However, just because one can build it and run it, doesn't mean that the organization is fully set up to support a new language or even a different version of a language.
We need to ensure that the language we choose is supported by the different infrastructure that plays a part in the wider SDLC:
- Artifact registries
- Security scanners
- Monitoring tools
In the same sense, it might be the organization itself forcing the change, because they're dropping support for our language of choice (or a particular version).
Languages and External Support
As we're choosing our language we must also understand if there are external constraints that we need to satisfy.
Some of these constraints might be hard. For example, we might have a hard dependency on a close source library that is only supported in a particular language, or maybe even a particular version of a language. In such cases, we must decide within those constraints.
In other cases, constraints might be softer. If our software is going to be shipped to external users packaged as an application, there might be pushback to change the runtime. For example, there might be pushback to require our users to change their Java Runtime Environment. In these cases, there might be valid reasons to push our users to make those changes, even against any pushback. A runtime reaching end-of-life is a very obvious one, but providing new features or better performance might make forcing the change more appealing.
Language Features
Once we have taken into account the constraints in which we can select the language based on the area that excites us developers: features!. What language provides the features that will make it easier to write the best software?
Do we want an object-oriented language like Java? or a more multi-purpose language that supports both an object and procedural approach like Python?
Does a particular runtime provide a better performance for our particular use case? What threading model works best for us? In Chapter 11 we take a look at the difference in threading models for the JVM, NodeJS, and Python.
Which ecosystem has the libraries and frameworks that will help us the most? For example, in the area of Data Science, Python has a very rich ecosystem.
And within one particular language, do we want to target a particular minimum version to get any new features that will make our lives easier?
- What language are we going to use?
- What version of the language are we going to target?
Choosing the Framework
Once we decide on a particular language to target, we move up to the next level of the foundation. In modern software development, we rarely build things from scratch, but rather leverage frameworks that provide a lot of core functionality so that we can focus on the functionality that will differentiate our software.
In choosing the framework we have to consider what services it provides and contrast that with the services that our application will need.
There are many different frameworks and many types of frameworks that provide different functionality. For example:
Many different types of frameworks:
- Dependency Injection
- Model View Controller (MVC)
- RESTful and Web Services
- Persistence
- Messaging and Enterprise Integration Patterns (EIP)
- Batching and Scheduling
Some frameworks will cover multiple areas, but many times we still have to mix and match. To select a framework or frameworks we need to determine the functionality that our application will use, and then select the
This must be done under the same constraints that we used to select our language:
- Knowledge and familiarity within our team
- Support within the company
- Compatibility with any external components with which we have a hard dependency
- If we're shipping our code to a customer, support among them
In the following sections, we're going to introduce the three frameworks that we will focus on.
Spring Boot
Spring Boot is a Java framework that packages a large number of Spring components, and provides "opinionated" defaults that minimize the configuration required.
Spring Boot is a modular framework and includes components such as:
- Spring Dependency Injection
- Spring MVC
- Spring Data (Persistence)
Many other modules can be added to provide more functionality.
Spring Boot is often used for RESTful applications, but can also be used to build other kinds of applications, such as event-driven or batch applications.
Express
Express (sometimes referred to as Express.js) is a back-end web application framework for building RESTful APIs with Node.js. As a framework oriented around web applications and web services, Express provides a robust routing mechanism, and many helpers for HTTP operations (redirection, caching, etc.)
Express doesn't provide dedicated Dependency Injection, but it can be achieved using core Javascript functionality.
Flask
Flask is a web framework for Python. It is geared toward web applications and RESTful APIs.
As a "micro-framework", Flask focuses on a very specific feature set. To fill any gaps, flask supports extensions that can add application features. Extensions exist for object-relational mappers, form validation, upload handling, and various open authentication technologies. For example, Flask benefits from being integrated with a dependency injection framework (such as the aptly named Dependency Injector).
- What features do we need from our framework or frameworks?
- What framework or frameworks are we going to use?
Other Frameworks
In this section, we introduced some of the frameworks that we're going to focus on throughout the book. We have selected these due to their popularity, but there are many other high-quality options out there to consider.
Libraries
A framework provides a lot of functionality, but there is normally a need to fill in gaps with extra libraries. Normally these extra libraries are either related to the core functional requirements or help with cross-cutting concerns.
For the core functionality, the required libraries will be based on the subject expertise of the functionality itself.
For the libraries that will provide more generic functionality, we cover cross-cutting concerns in future sections.
Version Control System
Keeping the source code secure is paramount to having a healthy development experience. Code must be stored in a Version Control System (VCS) or a Source Code Management (SCM) system. Nowadays most teams choose Git for their version control system, and it is widely considered the industry-wide de-facto standard. However, there are other modern options, both open source and proprietary, that bring some differentiation that might be important to your team. Also, depending on your organization you might be forced to use a legacy Version Control System, although this is becoming less and less frequent.
From here on out, the book will assume Git as the Version Control System.
Repository Structure
When we're getting ready to store our source code in our Version Control System, we need to make a few decisions related to how we're going to structure the code.
We might choose to have a single repository for our application, regardless of how many components (binaries, libraries) it contains. We can separate the different components in different directories while having a single place for all of the code for our application.
In some cases, it might be necessary to separate some components or modules into different repositories. This might be required in a few cases:
- Part of the code will be shared with external parties. For example, a client library will be released as open source, while the server-side code remains proprietary
- It is expected that in the future, different components will be managed by other teams and we want to completely delegate to that team when the time comes.
There's another setup that deserves special mention, and it's the monorepo concept. In this setup, the code for many projects is stored in the same repository. This setup contrasts with a polyrepo, where each application, or even each component in an application has its own repository. Monorepos have a lot of advantages, especially in large organizations, but the design and implementation of such a system is very complex, requires an organization-wide commitment, and can take months if not years. Therefore choosing a monorepo is not a decision that can be taken lightly or done in isolation.
| Pros | Cons | |
|---|---|---|
| One repo per application |
|
|
| One repo per module |
|
|
| Monorepo |
|
|
Git Branching Strategies
One mechanism that must be defined early in the development process is the Git branching strategy. This defines how and why development branches will be created, and how they will be merged back into the long-lived branches from which releases are created. We're going to focus on three different strategies that are well-defined:
GitFlow
GitFlow is a Git workflow that involves the use of feature branches and multiple primary branches.

The main or master branch holds the most recently released version of the code.
A develop branch is created off the main or master branch. Feature branches are created from develop. Once development is done in feature branches, the changes are merged back into develop.
Once develop has acquired enough features for a release (or a predetermined release date is approaching), a release branch is forked off of develop. Testing is done on this release branch. If any bugfixes are needed while testing the release branch a releasefix branch is created. Fixes must then be merged to the release branch as well as the develop branch. Once the code from the release is released, the code is merged into main or master. During the time the release is being tested, new feature releases can still occur in the develop branch.
If any fixes are needed after a release a hotfix branch is created. Fixes from the hotfix branch must be merged back into develop and main/master.
GitFlow is a heavy-weight workflow and works best for projects that are doing Semantic Versioning or Calendar Versioning.
GitHub Flow
GitHub Flow is a lightweight, branch-based workflow.

In GitHub Flow, feature branches are created from the main or master branch.
Development is done in the feature branches.
If the development of the feature branch takes a long time,
it should be refreshed from main or master regularly.
Once development is complete, a pull request is created to merge the code back into main or master.
The code that is merged into main or master should be ready to deploy. No incomplete code should be merged.
GitHub Flow works best for projects that are doing Continous Delivery (CD).
Trunk-Based
Trunk-based development is a workflow where each developer divides their work into small batches.

The developer merges their work back into the trunk branch regularly, once a day or potentially more often.
The developers must also merge changes from trunk back into their branches often, to limit the possibility of conflicts.
Trunk-based development is very similar to GitHub Flow, the main difference being that GitHub Flow has longer-lived branches with larger commits.
Trunk-based development forces a reconsideration of the scope of the tickets, to break up the work into smaller chunks that can be integrated regularly back into the trunk.
- What Version Control System will we use?
- How many repositories will our application use?
- Which branching strategy will the team use?
Project Generators
Most frameworks provide tools that make it easy to create the basic file structure. This saves the effort of having to find the right formats for the files and creating them by hand, which can be an error-prone process.
This functionality might be integrated as part of the build tools for your particular ecosystem.
For example Maven's mvn archetype:generate, Gradle's gradle init, and NPM's npm init will generate the file structure for a new project.
These tools take basic input such as the component's name, id, and version and generate the corresponding files.
Some stand-alone CLI tools provide this functionality and tend to have more features. Some examples are express-generatorhttps://expressjs.com/en/starter/generator.html, jhipster, and Spring Boot CLI.
Another option is to use a website that will build the basic file structure for your project from a very user-friendly webpage. For example Spring Initializr generates spring boot projects, and allows you to select extra modules.
Finally, your organization might provide its own generator, that will set up the basic file structure for your project, while also defining organization-specific data such as cost codes.
- What tool or template are we going to use to create the basic file structure of our component(s)?
Project Structure
The basic structure we choose for our code will depend on how our code will be used.
If we're creating a request processing application we can consider how the requests or operations will flow through the code, how the application is exposed, and what external systems or data sources we will rely on. A lot of these questions make us step into "architect" territory, but at this level, there's a lot of overlap.
The structure of our code will vary significantly if we're building a service compared to if we're building a library that will be used by other teams. How we structure the code might also vary if we're keeping our code internal, or if it's going to be made available to outside parties.
In terms of the project structure, the layout of the files should lend itself to easily navigating the source code. In this respect, the layout normally follows the architecture, with different packages for different architectural layers or cross-cutting concerns.
Given the large number of variations and caveats, we're going to focus on very basic for general purpose architecture that we detail in the next section.
Basic Backend Architecture
Code can always be refactored, but ensuring we have a sound architecture from the start will simplify development and result in higher quality. When we talk about higher-quality code, we mean not only code with fewer bugs but also code that is easier to maintain.
Applications will vary greatly, but for most backend applications, we can rely on a basic architecture that will cover most cases:

This architecture separates the code according to the way requests flow. The flow starts in the "Controllers & Endpoints" when requests are received, moving down the stack to "Business Logic" where business rules and logic are executed, and finally delegating to "Data Access Objects" that abstract and provide access to external systems.
Other classes would fall into the following categories:
- Domain Model
- Utility Classes and Functions
- Cross-cutting Concerns
In such an architecture, the file layout will look like this:
src
├───config
├───controllers
│ └───handlers
├───dao
│ └───interceptors
├───model
│ └───external
├───services
│ └───interceptors
└───utils
This structure is based on the function of each component:
config: Basic configuration for the application.controllers: Controllers and endpoints.controllers/handlers: Cross-cutting concerns that are applied to controllers or endpoints, such as authentication or error handling.dao: Data access objects that we use to communicate with downstream services such as databases.dao/interceptors: Cross-cutting concerns that are applied to the data access objects, such as caching and retry logic.model: Domain object models. The classes that represent our business entities.model/external: Represents the entities that are used by users to call our service. These are part of the contract we provide, so any changes must be carefully considered.services: The business logic layer. Services encapsulate any business rules, as well as orchestrating the calls to downstream services.services/interceptors: Cross-cutting concerns that are applied to the services, such as caching or logging.utils: Utilities that are accessed statically from other multiple components.
This file structure is only provided as an example. Different names and layouts can be used as needed, as long as they allow the team to navigate the source with ease. There will normally be a parallel folder with the same structure for the unit tests.
Controllers and Endpoints

Controllers and Endpoints comprise the topmost layer, These are the components that initiate operations for our backend service. These components are normally one of the following:
- The REST or API endpoint listening for HTTP traffic.
- The
Controllerwhen talking about MVC (Model View Controller) applications. - The Listener for event-driven applications.
The exact functionality of the component depends on how the type of application, but its main purpose is to handle the boundary between our application and the user or system that is invoking our service.
For example, for HTTP-based services (web services, MVC applications, etc), in this layer we would:
- Define the URL that the endpoint will respond to
- Receive the request from the caller
- Do basic formatting or translation
- Call the corresponding Business Logic
- Send the response back to the caller
For event-driven applications, the components in the layer would:
- Define the source of the events
- Poll for new events (or receive the events in a pull setup)
- Manage the prefetch queue
- Do basic formatting or translation
- Call the corresponding Business Logic
- Send the acknowledgment (or negative acknowledgment) back to the event source
In both the HTTP and the event-driven services, most of this functionality is already provided by the framework, and we just need to configure it.
There is one more case that belongs on this layer, and it relates to scheduled jobs. For services that operate on a schedule, the topmost layer is the scheduler. The scheduler handles the timing of the invocation as well as the target method within the Business Logic layer that will invoked. In such cases, we can also leverage a framework that will provide a scheduler functionality.
Business Logic

The middle layer is where our "Business Logic" lives.
This includes any complicated algorithm, business rules, etc.
It is in this layer that the orchestration of any downstream calls occurs.
The components in this layer are normally called Services.
This layer should be abstracted away from the nuanced handling of I/O.
This separation makes it easier for us to mock upstream and downstream components and easily create unit tests.
It is in this layer where the expertise of business analysts and subject matter experts is most important, and their input is critical.
Involving them in the design process, and working with them to validate the test cases. We go into detail about specific techniques in Chapter 5.
Data Access Objects

The bottom-most layer provides a thin layer to access downstream services. Some of these downstream services can be:
- Databases: If our service needs to read and write data from a database.
- Web Services: Our service might need to talk to other services over a mechanism such as REST or gRPC.
- Publishing Messages: Sometimes our application might need to send a message, through a message broker or even an email through SMTP (Simple Mail Transfer Protocol).
Using a Data Access Object helps to encapsulate the complexity of dealing with the external system, such as managing connections, handling exceptions and retries, and marshaling and unmarshalling messages.
The objective of separating the data access code into a separate is to make it easier to test the code (in particular the business logic code). This level of abstraction also makes it easier to provide a different implementation at runtime, for example, to talk to an in-memory database rather than to an external database.
In a few cases, there might not be a need for a Data Access Object layer. For applications that rely only on the algorithms present in the Business Logic layer and don't need to communicate to downstream services, the Data Access layer is irrelevant.
Domain Model
The Domain Model is the set of objects that represent entities we use in our systems. These objects model the attributes of each object and the relationships between different objects. The Domain Model defines the entities our service is going to consume, manipulate, persist, and produce.
In some cases, it's important to separate the external model from the internal model. The external model is part of the contract used by callers. Any changes to the external model should be done with a lot of care, to prevent breaking external callers. More details on how to roll out changes to the external model can be found in Chapter 14 The internal model is only used by our application or service and can be changed as needed to support new features or optimizations.
In traditional Domain-Driven Design (DDD), the Domain Model incorporates both behavior and data. However, nowadays most behavior is extracted to the business layer, leaving the Domain Model as a very simple data structure. Nonetheless, the correct modeling of the domain objects is critical to producing maintainable code. The work of designing the Domain Model should be done leveraging the expertise of the business analysts and subject matter experts.
The Domain Model can be represented by an Entity Relationship Diagram (ERD).

Utility Classes and Functions
In this context "utility" is a catch-all for all components (classes, functions, or methods) that are used to perform common routines in all layers of our application.
These utility classes and functions should be statically accessible. Because of their wide use, it does not make sense to add them to a superclass. Likewise, utility classes are not meant to be subclassed and will be marked as such in languages that support this idiom (for example final in Java).
Cross-Cutting Concerns
Cross-cutting concerns are parts of a program that affect many other parts of the system. Extracting cross-cutting concerns has many advantages when writing or maintaining a piece of software:
- Reusability: Allows the code to be used in different parts of the service.
- Stability and reliability: Extracting the cross-cutting concern makes it easier to test, increasing the stability and reliability of our service.
- Easier extensibility: Using a framework that supports cross-cutting concerns makes it easier to extend our software in the future.
- Single responsibility pattern: It helps ensure that our different components have a single responsibility.
- SOLID and DRY: It makes it easier to follow best practices such as SOLID and DRY(Don't Repeat Yourself).
To implement the cross-cutting concerns we want to leverage our framework as much as possible. Many frameworks provide hooks that we can use to save time. However, we also want to understand how the framework implements the hooks, to be able to debug and optimize these components. We explore in more detail some of the techniques used by common frameworks in Chapter 13.
There are some disadvantages to abstracting away cross-cutting concerns, especially when relying on "convention over configuration". Some developers might have a harder time following the logic if they don't understand the framework. Also "convention over configuration" often conflicts with another software design principle: "explicit is better than implicit". As Senior Software Developers, we must balance the ease of maintaining and ease of testing with the technology and functionality we're bringing into the code base.
The design of how the cross-cutting concerns will be implemented is a vital part of the architecture of the application. These are important decisions, but one of the advantages of decoupling this functionality into separate components, is that it makes it easier to fix any shortcomings.
How cross-cutting concerns are supported varies from framework to framework. Here are some common mechanisms:
- Aspect Oriented Programming
- Filters and Middleware
- Decorators and Annotations
These mechanisms are explained in detail in Chapter 13.
In the next sections, we'll introduce some core cross-cutting concerns. Many decisions should be made for each one of these cross-cutting concerns, but those decisions are formally listed in the respective in-depth chapters, rather than the introductions from this chapter.
Logging
Logging information about the application's behavior and events can be helpful for debugging, monitoring, and analysis. Logging is a cross-cutting concern because you want to abstract away and centralize the details of how the logging is done. These details include:
- Which library should we choose?
- Where should we write to? Most libraries allow the configuration of log sinks. Depending on how our application is configured, we might want to write or append to standard output to be picked up by an external logging agent. In other cases, we'll write directly to our logging service.
- What format should we use? Most logging libraries use plain text by default, and we can configure that plain text format with a custom pattern. Depending on which logging service we're using, we might choose a structured logging format such as JSON to be able to emit extra metadata.
The actual logging of the messages is normally left up to individual methods, but an application-wide vision is needed. For example, a Senior Developer or Architect should decide if context-aware logging is going to be used, and if so what information should be recorded as part of the context. Context-aware logging is a mechanism to enrich log messages with data that might be unavailable in the scope in which the log statement executes. This is also sometimes referred to as Mapped Debugging Context. We discuss this technique in more detail in Chapter 19.
Security
Ensuring the confidentiality, integrity, and availability of data is a critical concern for many applications. This can involve implementing authentication, authorization, and encryption mechanisms.
As Senior Developers we have to decide what mechanisms are necessary, and where they should be implemented.
For example, one of the decisions that is commonly relevant for a backend service is how will users authenticate to use our application.
There are many options to consider:
- Usernames and Passwords
- Tokens (for example OAuth or JWT)
- Certificate-based authentication
- OpenId or SAML
Due to the risks involved, it's better to use an existing framework for security rather than writing our own. Many frameworks provide out-of-the-box solutions or provide hooks to support a modular approach.
For example in the Java/Spring ecosystem Spring Security provides a very feature-rich solution.
Neither Flask nor Express provides an out-of-the-box security solution but rather provides hooks into which third-party solutions can be adapted. These third-party solutions are normally applied as middleware, functions that have access to the request and response objects, and the next middleware function in the application’s request processing chain.
Where should security be implemented?

Security can be applied at different layers. However it is mostly applied at the Controller and Endpoints layers, and in the Business Logic layer less often. In general the closer to the user the better. In some cases, the authentication and authorization is offloaded from the application, and handled by an API Gateway or a Service Mesh.
Security is a very broad topic, and there are many specialized sources on the topic, however, we do talk more in detail in Chapter 9.
Caching
Caching can help us achieve two main goals, improve performance and improve reliability. Caching can improve the performance of an application by reducing the number of trips to the database or other back-end systems. Caching can also improve the reliability of an application by keeping a copy of data that can be used when downstream services are unavailable. However, caching comes with a significant amount of extra complexity that must be considered.
There are only two hard things in Computer Science: cache invalidation and naming things.
-- Phil Karlton
Where should caching happen in a back-end application?
Caching can be implemented at every layer of the application, depending on what we're trying to achieve. However, it's best to not implement caching directly on the Data Access Objects, to maintain a single responsibility.
Caches can be shared across multiple instances or even multiple applications. Caches can also be provisioned on a per-instance basis. All of these parameters determine the effects caching will have on reliability, scalability, and manageability. Caching also introduces the need to consider extra functionality, for example, to handle the invalidation of entries that are no longer valid or stale.
Caching is a complicated topic with many implications, and we just scratched the surface here. We talk more in detail in Chapter 11.
Error Handling
Error handling is often overlooked as a cross-cutting concern, but a good setup from the beginning will make the application more maintainable and provide a better user experience in the worst moments. First and foremost, error handling is about trying to recover from the error if at all possible. How we do this depends greatly on our application and the type of error.
However, error handling is also about handling cases when we can't recover from the error. This entails returning useful information to the user while ensuring we don't leak private or sensitive information. Approaching error handling as a cross-cutting concern can help us simplify our code while providing a homogeneous experience for our users, by allowing us to handle errors regardless of where they occur in the application.
As part of the recurring theme, we should leverage our framework to simplify the work of handling errors. Our framework can help us map exceptions to HTTP return codes. The framework can help us select the proper view template to render user-readable error messages. Finally, most frameworks will provide default error pages for any exception not handled anywhere else.
For example, in a Spring-based application we can use an HandlerExceptionResolver
and its subclasses ExceptionHandlerExceptionResolver,
DefaultHandlerExceptionResolver,
and ResponseStatusExceptionResolver.
Express provides a simple yet flexible error handling mechanism, with a default error handler and hook to write custom error handlers.
By default, Flask handles errors and returns the appropriate HTTP error code. Flask also provides a mechanism to register custom error handlers.
If we refer to the core architecture we proposed, where should error handling be done?

Normally we want to handle unrecoverable errors as close to the user as possible. We do this have bubbling up exceptions up the stack until they are caught by an Exception Handler and properly dealt with. If we're talking about recoverable errors, we need to handle them in the component that knows how to recover from them, for example by retrying the transaction or using a circuit breaker pattern to fall back to a secondary system.
More detail on error handling as a cross-cutting concern can be found in (Chapter 12)[./chapter_12.md#error-handling].
Transactions
Transactions ensure that changes to data are either fully committed or fully rolled back in the event of an error, which helps maintain data consistency. Given the rise of NoSQL databases, transactions are not as widely used, but they're still very relevant when working with a traditional RDBMS (relational database management system).
Once we have determined the data sources that we will be interacting with, we have to determine if they support transactions. For data sources that don't support transactions, we have to think of other ways to reconcile failed updates.
Transactions can encompass a single data source or multiple data sources. If we have transactions across multiple data sources, we have to determine if they support a global transaction mechanism such as XA.
If we're going to use transactions, we need to select a transaction manager and integrate it into our application. If we're using a transaction manager, we must also decide how we're going to control the transactions. Transactions are either controlled programmatically or declaratively. Programmatic transactions are explicitly stated and committed. Declarative transactions are delineated by the transaction manager based on our desired behavior as indicated by special annotations (such as Transactional in Java).
Where should transaction control happen?

Transaction control normally happens in the Business Logic layer, or the gap between the Business Logic layer and the Data Access Objects layer. It is generally a bad idea to control transactions from the Controller and Endpoints layer since it would require the caller to know something about the internal workings of the lower layers, breaking the abstraction (also known as a leaky abstraction).
More details on transactions can be found in (Chapter 16)[./chapter_16.md#transactions].
Internationalization or Localization
Internationalization (sometimes referred to as "i18n") and Localization (sometimes referred to as "l10n") relate to applications that need to be used by people in different countries to be designed to handle different languages, time zones, currencies, and other cultural differences. These are very important concepts within software development but are most relevant for front-end development. Given the focus of the book on back-end development, the scope is much more limited and mostly relevant for systems that use "Service Side Scripting". In the cases where we use Server Side Scripting, the framework that we use can help us select the right template and format dates and numbers appropriately.
The concepts of internationalization or localization can also affect some of the data we work with, such as the currency that use. If our application is purely an API-based service then dates are normally returned in a standard format, and formatted by the client.
If using Spring MVC as part of your Spring application, you can use the Locale support to automatically resolve messages by using the client’s locale.
Neither Flask nor Express provide locale resolution support out of the box but can be provided by a third-party add-on.
Tools Referenced
- Spring Boot Open-source framework built around the Spring ecosystem. Mostly used to create web applications or web services, but can be used for other types of applications.
- Express Back-end web application framework for building RESTful APIs with Node.js.
- Flask A micro web framework written in Python.
Videos
From the Ground Up
From the Ground Up, continued
Automating the Build
Computers help us automate repetitive actions. As a developer, one of the most repetitive actions is to compile or build our code. Therefore automating the build process of our code is one of the first steps we should take. Nowadays most build processes are at least somewhat automated, but it's important to understand the nuances of the process to ensure that our automation works in our favor.
Throughout this chapter, keep in mind that automating the build has two purposes: make it easy for your peer developers to build the component, and have the build invoked by your CI (Continuous Integration) system. In a later chapter we go into detail about Continous Integration, but for now, we will only focus on the building part.
In larger projects, developers will only execute some of the tasks locally, while the CI system will execute all of them. In smaller projects, especially projects that have only a single developer, all of the tasks will be executed by the developer from their local machine.
Why is This Important?
In the modern world, the productivity of developers is paramount. As Software Developers, our time as well as the time of our teammates is the most valuable resource. Manually building our codebase over and over again provides no enduring value. Activities that must be done manually over and over again and provide no enduring value are sometimes referred to as "toil". Removing toil respects the time of our fellow developers. Improving developer productivity has always been relevant, but it has gained steam lately as part of the nascent discipline of "Developer Productivity Engineering" or "Developer Experience Engineering".
In their day to day, developers will run the build process multiple times, to verify the changes that they are incrementally making. Automating this process is key not only for developer productivity but also for developer satisfaction.
Build Tools
To automate the build, we always leverage a tool, from a simple bash script to a complex build tool with its ecosystem. In this chapter, we cover build automation tools, which are different from CI tools, which we cover in chapter 14.
Normally, what do we need our build tool to do:
- Fetch and manage dependencies
- Build the code
- Package the code
- Run tests
- Generate reports
As we can see from this short list, our "build tool" needs to do a lot more than just build the code.
There are a lot of different build tools to choose from. A big factor in choosing your build tool is the language your component is written. In fact, for some languages you don't require to be "built", but instead we can leverage tools that will manage our dependencies, as well as orchestrate other operations of the software development lifecycle.
For example, in Python pip is traditionally used to install dependencies.
In Node npm is used to manage dependencies as well as orchestrate other actions.
While JavaScript code normally doesn't have to be compiled, TypeScript is normally compiled into JavaScript.
If we're using TypeScript, npm can be configured to compile the code.
For compiled languages (C, C#, Java, Go, etc...) you have a lot more choices, since the build is a more involved process that many organizations or individuals have tried to improve in one way or another.
Some of the choices are strongly linked to a particular ecosystem. For example, both Apache Maven and Gradle are tightly coupled with the Java ecosystem. These tools can be extended to handle languages outside of their main ecosystem, but it's not as well supported.
Some tools are designed independently from any ecosystem and can support multiple languages.
Arguably the most widespread general-purpose build utility is (make)[https://www.gnu.org/software/make/], primarily due to its early inclusion in Unix.
Newer tools are also available, such as (Bazel )[https://bazel.build/].
Bazel is based on the internal Google build tool called Blaze and is a popular option when implementing monorepos.
Generally, we want to select the tool that will allow us to build our artifacts most simply. In parallel, we also want to select the tool that will allow us to run the unit tests for our software most simply.
Tools like Maven or Gradle will allow us to do both: build the code and run unit tests.
If we're using npm, it can run our tests, and it can also compile our code if we're using TypeScript.
In the Python ecosystem, generally, there is no build tool, instead relying on virtualenv to manage virtual environments, and pip to manage dependencies.
In these cases, tests are just normally executed from the command line using the python executable.
During the execution of a build different types of artifacts will be generated:
- Binaries
- Container images
- Deployment descriptors
- Libraries
- Documentation
- Testing results
- Code quality results
- What artifacts do we need to build?
- What tool are we going to use to build the artifacts?
Build Process
Setting up the whole build process can be broken into seven steps, which we'll review in detail in subsequent sections:

Component Metadata
All software (beyond trivial scripts), should have some kind of metadata that identifies it. The minimum information is normally:
- Component name or id: The name of the component, which doesn't have to be globally unique, but should be unique within the group it belongs.
- Group name or id: The unique base name of the company or team that created the project.
- Version: Version of the component. More information on how to select a version can be found in the component version section.
The metadata can also include other useful information such as the description, links to documentation, the authors of the component, etc.
This data is normally stored in a specially named file, depending on the build tool that will be used.
- In Java using Gradle: [
build.gradleorbuild.gradle.kts](https://docs.gradle.org/current/userguide/tutorial_using_tasks.html - In Java using Maven:
pom.xml - In Node using npm:
package.json - In Python:
pyproject.toml
Most components will also specify any needed dependencies, either in the same file that holds the metadata or in a separate file (for example requirements.txt in Python).
In this same file, we can normally specify any values that must be overridden to alter the default behavior of the build tool.
For example, if our project has a non-standard structure and the source code is located in an unexpected directory, we must ensure the toolchain is aware of this setup.
The metadata is used by the build system to properly configure the toolchain, execute the build, and create the relevant artifacts.
Most of the metadata will be defined manually and persisted in a file. However, in some cases, some of the metadata will be determined dynamically during the build process. For example, the build process may want to record the current time and date, or the git branch and revision that is being built.
- What is the component name or id?
- What is the group name or id?
- What is the version of our component?
- Do we need to override any defaults for our build tool?
- Is there any other useful metadata that should be added?
Component Version
Software versioning is important because it helps both users and developers track the different releases of the software. Users rely on software developers to keep software components up to date, and they expect a methodical way of understanding when and what updates are released. Developers need a methodical way to identify what release (or releases) of a software component have a particular feature or bug.
Therefore we must use a sensible versioning scheme. There are two main versioning schemes that we will be exploring in detail:
- Semantic Versioning: A set of rules how version numbers should be assigned and incremented. More details here.
- Calendar Versioning: A set of practices to create version numbers based on the release calendar of your software component. More details here.
To choose the right versioning scheme for your application, it's vital to understand how your users consume your application or component. Are your users more interested in knowing when they should upgrade the application, or are they more interested in what changed? The frequency and consistency of your releases will also help you determine if a semantic or calendar versioning scheme is better for your team and your users.
As always keep context in mind. This might already be defined in your organization.
Semantic Versioning
Semantic Versioning (also referred to as SemVer) provides a simple set of rules and requirements that dictate how version numbers are assigned and incremented.
Semantic Versioning assigns a particular meaning to each segment of the version string.
In Semantic Versioning, versions are specified in the following format: MAJOR.MINOR.PATCH.
Each one of those components has a particular meaning:
MAJOR: The major version must be increased when incompatible API changes are introduced.MINOR: The minor version must be increased when we add functionality in a backward-compatible manner.PATCH: The patch version must be increased when we release backward-compatible bug fixes.
Given the prevalence of semantic versioning in the software world, if a version string looks like SemVer, make sure it behaves like SemVer.
We must keep in mind that versioning can also be a marketing concern.
For example, version 2.0.0 sounds more exciting than 1.1.0.
Therefore there might be external forces driving the versioning.
Software development is never really done.
There's always something else we want to add, or improve.
Many developers are therefore hesitant to release a 1.0.0 version.
However, if your software is being used in production, or if users depend on your API, you're already worrying about backward compatibility,
your software should already be at least 1.0.0.
More information can be found on the Semantic Versioning website: https://semver.org/.
Calendar Versioning
Calendar Versioning (also referred to as CalVer) is a scheme based on the release calendar of your software, instead of arbitrary numbers. There are multiple calendar versioning schemes. CalVer does not provide a single scheme, but rather a set of practices that can be leveraged to fit the requirements of different users and organizations.
CalVer makes it easier for users to understand at a glance how up-to-date their software component is. The scheme is especially useful for applications that require manual updates. The information contained in the version can make it easier for users to gauge how important is it for them to update the application. CalVer makes it easy for a user to understand how many months (or years) behind the latest release they are.
Central to CalVer is a set of fields that can be used:
MAJOR: The major segment is the most common calendar-based component.MINOR: The second number.MICRO: The third and usually final number. Sometimes referred to as the "patch" segment.MODIFIER: An optional text tag, such as "dev", "alpha", "beta", "rc1", and so on.
There are many examples of popular software packages that leverage CalVer:
- Ubuntu:
22.04 LTS - youtube-dl:
2021.05.16 - IntelliJ IDEA:
2023.1.1
More information can be found on the Semantic Versioning website: https://semver.org/.
Toolchain Setup
Part of setting up the build is ensuring that the right tools are available. This is often called the "toolchain". The toolchain is a set of programming tools that are used to perform the set of tasks required to create a software product. The chain part comes in because in most cases the output of a tool is used as the input of the next tool in the chain.
The toolchain, in the broadest sense, is composed of multiple components. For example:
- The build tool itself
- Preprocessors
- Compilers and linkers
- Required runtimes
As part of our role as senior software developers, we must ensure all of the developers have access to the toolchain, easily and consistently.
There are many options to achieve this. The right option will depend on the individual circumstances of the development team. For example, making a toolchain available to a team that is part of a large organization with a well-established I.T. support department could be very different to making the toolchain available to a team of a fledging startup where developers are using their own personal laptops for work.
Some of the options to distribute the toolchain include:
- Have developers install things manually on their computers.
- Have the I.T. support department preinstall the tools on the computers that are distributed to developers.
- Use a wrapper to download the toolchain.
- Use containers to make the toolchain available, in particular via dev containers.
For the first option, where developers install their toolchain manually, good documentation is critical to achieve any kind of success. It's a workable solution when other options are not available, but is very manual and error-prone.
The second option, where we can leverage the I.T. support department, we can leverage the work that has already been done in the organization to manage the software that is installed in the organization-owned devices. Most large I.T. support departments have sophisticated tooling that makes installing the toolchain possible, but working with the I.T. department might add an extra layer of complexity and reduce flexibility. Due to corporate policies, this might be the only way of installing any piece of software (including our toolchain) into organization-owned devices.
The third and fourth options are explored in more detail in the following sections.
Wrappers
A wrapper is a very simple script that invokes a declared version of a tool. If the tool is not available locally, the wrapper will download it beforehand. Wrappers are very popular in the JVM ecosystem, in particular for Maven and Gradle.
The wrappers for both Maven and Gradle require the right JVM (Java Virtual Machine) to be installed already. This requires some mechanism to install the JVM in the developer workstations, but once the JVM is installed, it's trivial to ensure all of the developers are using the right version of Maven or Gradle.
To use a wrapper, a very small executable jar is committed into the source code.
There is normally also a Shell or Batch script that is used to make it easier to invoke the wrapper.
Committing binary files like a jar file is normally discouraged, but this is an example where an exception makes sense to ensure the proper toolchain is installed when needed.
The wrapper is configured via a file, which contains information about which version of the tool must be executed. The configuration file also contains information regarding how the build tool will be downloaded, for example, any proxies that should be used, or custom locations to fetch the files from.
For the Gradle wrapper, the configuration is located in a file called gradle-wrapper.properties inside a directory called wrapper.
For the Maven wrapper, the configuration is located in a file called maven-wrapper.properties, inside a directory called .mvn/wrapper/.
When the wrapper is invoked, the wrapper will verify the configuration file to determine what version of the tool is to be invoked. If the particular version of the tool is not locally available, it will be downloaded. The wrapper will then execute the tool, by passing through any options that were specified on the command line and are not wrapper-specific.
The build tool will download other dependencies and perform the required build steps.
Dev Containers
Development Containers (also called Dev Containers for short) is a specification that allows using containers as a full-featured development environment, including providing the full toolchain.
To use Dev Containers, the toolchain is defined as a set of containers.
The containers are configured in a file called devcontainer.json.
A sample devcontainer.json file is shown below:
{
"image": "mcr.microsoft.com/devcontainers/typescript-node",
"customizations": {
"vscode": {
"extensions": ["streetsidesoftware.code-spell-checker"]
}
},
"forwardPorts": [3000]
}
The full configuration documentation can be seen here.
Once the container is configured in the devcontainer.json file, your IDE will manage a running instance of the container to provide the required toolchain.
Dependencies
Build time dependencies are another area worth automating. In particular, automation is important to ensure that builds are reproducible, as when we release software we want to be sure that we have control over what is released.
A reproducible build is a build in which we can recreate our output artifacts to the bit level given the same inputs: the same source code, build environment, and build instructions. All of these inputs must be versioned in a source control system (such as Git).
In some cases, a development team might be ok with builds that are not fully reproducible. Especially during active development, the team might want to have access to the latest version of libraries that are getting developed in parallel. For example, using non-deterministic library versions makes it easier to integrate changes from other teams before said libraries are finalized and released.
In such cases, when a bug is caused by a library, the problem might be solved by just rebuilding the application, without making any changes to the inputs stored in source control. This happens because rebuilding the application will pull the latest version of the library. Of course, the flipside of this is that rebuilding the application could result in the introduction of a bug or incompatibility.
If non-deterministic library versions are used when building during development, it's vital to ensure that a deterministic build is done when building release artifacts. The exact mechanisms vary from language to language. In the following sections, we explore some of the mechanisms for Java, NodeJS, and Python.
Java Libary Versioning
In Java, when using Maven or Gradle, library versions can be specified as a SNAPSHOT.
The SNAPSHOT version precedes the actual release version of the library.
For example 1.0-SNAPSHOT is 1.0 under development.
The reference to SNAPSHOT dependencies should only exist during development.
It is normally recommended not to rely on SNAPSHOT dependencies not developed by your team/organization, as the release cadence of a third-party library might be hard to align with the release of your software.
Any reference to a SNAPSHOT dependency can cause the build to be "not reproducible".
With this in mind, remove SNAPSHOT as soon as possible.
Both Maven and Gradle support range versions for dependencies, although their use is much less common than using exact versions and SNAPSHOT libraries.
More documentation about range versions can be found in the respective documentation for Maven and Gradle.
Gradle also provides a mechanism to lock range versions to provide reproducible builds while maintaining some flexibility.
NodeJS Libary Versioning
In the NodeJS ecosystem, npm has the concept of library version resolution based on ranges and "compatible" versions.
NodeJS libraries are expected to be in SemVer format and are specified in the dependencies section of the package.json file.
Within the SemVer format, the many different requirements can be expressed:
version: Must matchversionexactly>version: Must be greater thanversion>=version: Must be greater or equal thanversion<version: Must be lower thanversion<=version: Must be lower or equal toversion~version: Accept only patch updates^version: Accept minor and patch updateslatest: Always get the latest
More information can be found on the specification of the package.json file.
To be able to support reproducible, npm maintains the package-lock.json file.
The lock file maintains exact versions of the dependencies that have been installed.
While package.json is meant to be edited by developers, the lock file is maintained by npm after most commands that manipulate the dependencies.
For example, adding a new dependency with npm install will update the pacakge-lock.json file.
Running npm install without adding any new dependencies will update the pacakge-lock.json file with the latest versions that are available within the ranges defined in the package.json file.
To perform a "reproducible build", for example in the Continous Integration server, the npm dependencies with npm ci.
This command will install the exact versions defined in the package-lock.json file.
For this reason, it is recommended to persist the package-lock.json file in source control.
Python Libary Versioning
For Python applications, pip allows using ranges (both inclusive and exclusive) and "compatible" versions.
For example:
~= 2.2: Any2.Xversion greater than2.2~= 1.4.5: Any1.4.Xversion greater than1.4.5> 1.4.5: Any version greater than1.4.5(exclusive range)>= 1.4.5: Any version greater than or equal to1.4.5(inclusive range)
The pip Version specifiers are described as part of the Python Packaging User Guide,
Reproducible builds can be achieved by "freezing" the requirements file, using pip freeze > requirements.txt.
The resulting requirements.txt file will only contain exact versions as installed in the current environment.
Installing from a fronzed requirements file will result in a deterministic set of libraries.
In the CI environment, a frozen requirements file should be used to ensure the build is reproducible.
More information about the freeze command can be found in the pip documentation.
Code Compilation
For compiled languages, code compilation is the key step where the source code the developer writes gets turned into a binary format that can be executed. This applies to languages like Java and C/C++, but normally not to interpreted languages like NodeJS or Python.
For some interpreted languages, there are some exceptions. For example to compile TypeScript into JavaScript.
In the compilation step, our role as senior developers is to ensure that the build can compile the code without any manual input. This requires that all of the inputs are defined and stored in source control:
- Source files
- Flags
- Preprocessors
Most of the flags and preprocessors used are the same regardless of which environment you are building in, but there might be some flags that will vary from environment to environment, due to different Operating Systems or different hardware architectures. This is more significant for languages that produce native binaries (such as C/C++, Go, Rust) as opposed to languages that compile into bytecode that is executed by a runtime (such as Java and other languages that compile to JRE's bytecode format).
For languages that compile native binaries, there's language-specific tooling that helps determine the proper set of flags that are required depending on the current environment. One prominent example is autoconf.
The actual compilation process depends on each language.
- What commands and parameters do we need to persist to source control to ensure compilation can be executed automatically?
- Do we need to use some mechanism to account for compilation in different operation systems or architectures?
Tests
Testing is critical to producing high-quality software. Code must be tested, and the testing must be ingrained in the build process to reduce friction and minimize the likelihood of tests becoming stale. There are many types of tests, but in this section, we focus on "functional tests", a type of testing that seeks to establish whether each application feature works as per the software requirements. In general, functional tests are divided into two main types:
- Unit tests: Tests that can run quickly and depend on few if any external systems.
- Integration tests: Tests that require significant external systems or large infrastructure.
Unit tests are normally implemented near the code they are testing, while integration tests might be implemented as a separate project. To provide the most value, tests must be easy to run. And just like with compilation, all tests that don't require large infrastructure or external systems should be automated through our build system so that they can be run with a single command.
Integration tests should also be automated but given the complexity and external dependencies, integration tests tend to be run outside of the regular build. Instead, they are automated to be run by the CI system.
In later chapters, we go into much more detail about Unit Tests and Integration Tests.
Code Quality
Writing code is hard, but maintaining it tends to be even harder. High-quality code should do more than just run. We need to ensure that our code is reliable, secure, easy to understand, and easy to maintain. To ensure we're producing high-quality code, we can leverage tools that will perform automated checks to provide objective metrics regarding the quality of the code and any areas that need attention.
Keeping track of the quality of our code using objective metrics allows us to keep technical debt from creeping in.
In Chapter 8 we go into detail on how to use code quality tools to improve the quality of our code.
- What code quality tools will we integrate?
- How will these code quality tools be executed?
Developer Experience
Automating the build ties back to the idea of Developer Experience, because the time of developers is extremely valuable. While automating the build is generally a prerequisite to improving the productivity of developers,
As a senior developer, it is part of our role to ensure that the tools and processes are maintaining a positive developer experience. Developer experience should be an ongoing concern.
Part of this implies ensuring the build automation supports the experience of the developers. For example, we want to ensure that there are checks that prevent developers from getting a broken build. Guardrails should be set up to prevent merging breaking changes, for example, changes that won't compile or won't pass the automated tests. Source control systems can be configured to prevent merges of changes that haven't passed the automated tests run in the CI.
Developers should also have good visibility into the CI system to be able to get information about builds. Nothing kills productivity and morale like debugging a broken build without good visibility.
As part of the automation of the build, it's important to gather metrics to prevent the developer experience from degrading. These metrics will allow us to detect if builds are getting slower, or failing more often. Detecting these kinds of regressions is the first step to be able to resolve issues that can creep in and degrade the developer experience.
If issues are detected early, it is easier to detect the root cause. Root causes for slower builds are normally related to a change. For example:
- A large dependency being added which must be downloaded and is not properly cached
- Caches not working as expected
- Upgrades to a part of the toolchain
In other cases, an external system outside of our control can be the culprit of the slowness. To identify the issue, good metrics are vital. Metrics should be granular enough to measure the latency of individual tasks within our build process.
To resolve slow builds, many techniques can be used to speed up the build and improve the developer experience. The actual techniques depend on the specific build tool being used, but some examples include:
- Using caches (both local and remote) to speed up some of the build steps
- Limit the components that are built locally for each project or module, instead of downloading already-built modules from artifact registries
- Limit the code that is tested locally for each project or module
- Offload some of the tasks to remote executors that can provide more computing power or more parallelization
- What metrics concerning the build will be collected?
- Where will those metrics be collected? (only in the CI server or also as the developer builds locally)
Tools Referenced
Videos
Automating the Build
Automating the Build, continued
Keeping the Team Productive
In the previous chapter, we introduced the concept of "Developer Productivity Engineering" or "Developer Experience Engineering", and how automation is a key piece to supporting the developer experience. In this chapter, we talk about how we can support the developers as they navigate the interaction between the code they're writing and the external systems that other teams or organizations manage.
Why is This Important?
In any discipline, project management is hard. And project management in software engineering tends to be even more chaotic and nuanced, due to the shifting nature of IT systems. Software projects tend to rely on complex infrastructure and have many dependencies and access requirements that might not be straightforward to attain. To successfully lead a development effort, it's vital to understand the importance of identifying external dependencies in the Software Development Lifecycle (SDLC). In this chapter, we'll explore different strategies to work around the dependency misalignments that often arise as we're working on complex (or not so complex) software projects.
How Software is Developed
If you have worked in software development for any amount of time, you have likely heard the term "waterfall", "waterfall development", "waterfall model" or a similar term. The waterfall model is sometimes presented as a methodology, but in reality, it's a description of the different operations in the software development process that tend to align themselves. The model was originally described by Winston W. Royce in his 1970 article, "Managing the Development of Large Software Systems".
Royce himself didn't advocate for the waterfall model as an ideal approach. He highlighted its limitations and argued for an iterative approach with feedback loops.
The waterfall model as described by Dr. Royce, is rooted in sequencial tasks where the output of one step feeds into the next step:

This model rarely works as expected, because many situations are common in the day-to-day:
- Mismatched timelines: Different teams have different priorities, and the hard dependencies we have on the work of other teams might not be aligned with the priorities the other team has.
- Mismatched requirements: As different components are built, competing priorities will likely result in mismatched requirements that will have to be reconciled. The product team and the developers might look at the same requirement and understand something different.
- Gaps: Requirement gathering and design exercises are meant to ensure no gaps in the required functionality exist, but as no communication is ever perfect gaps are bound to exist. Those gaps will have to be filled somewhere, most likely by the team that has the greatest need.
- Delays: No matter how well software projects are estimated, there is always the chance of delays. These delays will then have downstream repercussions as other teams have to adjust their own schedules.
- Bugs: Writing software is hard and bugs are to be expected. However, the extent and impact of the bugs are always a big unknown that will have to be addressed.
Given the limitations that the waterfall method brings, a series of lightweight development methodologies arose in the industry. Most of these methodologies can be grouped under the umbrella term "Agile Development". Agile development is supposed to help us overcome the limitations of the waterfall model by :
- Making it easier to adapt to change: Agile methodologies take change for granted and make adapting to constant change part of the methodology. Agile development is especially well-suited for projects where requirements are likely to change. The iterative nature of agile development allows teams to quickly adapt to changes in requirements without disrupting the overall project timeline.
- Improving communication: Agile methodologies recognize that the best way to communicate the progress in the development of a software component is by demonstrating the progress. Constant feedback loops minimize the effort required to adapt to change. Agile development involves regular collaboration between the development team and the customer or product team, which helps to ensure that the final product meets the user's needs. This can lead to increased customer satisfaction and loyalty.
- Reduces risk of defects: Agile development encourages developers to test their code frequently, which helps to catch defects early on. This can save time and money in the long run, as it reduces the need for costly rework. By reducing the size of the changes, the overall risk of introducing defects is reduced by the nature of deploying smaller changes.
- Increases morale of the team: Agile development is a more collaborative and less stressful environment for developers. Seeing constant progress and reducing the uncertainty of long-term plans increases the morale of the team.
Ironically, these lightweight mechanisms make it more likely that development efforts will be completed on time and within budget. Agile methodology helps to ensure that projects are completed on time and within budget. Agile development breaks down projects into smaller, more manageable tasks, which makes it easier to track progress and make adjustments as needed. This can help to reduce the risk of scope creep and delays.
In the real world:
- Schedules slip
- Priorities change
- Things have to be redone
Breaking up projects into small chunks of work that can be completed at short intervals (normally named "sprints") that can deliver meaningful functionality that can be demoed allows us to reduce misunderstandings, limit the amount of rework that must be done, and deliver quicker.
This is not meant to be a full explanation of the Waterfall of Agile methodologies. There are plenty of books already diving into this subject, but as a Sr. Sofware Developer, we must have a solid understanding of how to apply Agile methodologies, and how it counter the most serious issues that occur when operating using a waterfall methodology.
Clear Goals and Expectations
Regardless of the methodology in use, it's vital to ensure that we get clear goals and expectations as move forward. While some very ambitious projects will lack clarity on what the end goal looks like, we must define realistic short-term goals and expectations that will provide feedback for us to clarify and validate the long-term vision that we're working on.
Regular feedback can be gathered from many sources. For example:
- From the code itself: Automated tests and code quality tools can give us concrete data on our progress and the quality of the code we're delivering.
- From stakeholders and SMEs: Performing regular demos (normally after each sprint of work) will give us the best chance to align expectations between the product team and the developers.
- From peer teams: When we have tight dependencies with peer teams, having regular sync meetings with these teams will help us provide and receive feedback as we move forward.
- Within the team: Having daily standups where developers can share what they have done and what they're working on provides an excellent opportunity to provide and receive feedback from other developers who are working on related areas of our application or component. Just remember to park those conversations until after the standup is complete to avoid slowing down everyone in the team!
Regular feedback allows us to shift change left. The sooner we identify an issue, the simpler and cheaper it is to fix.
To make this feedback loop efficient and meaningful, developers must be empowered and have the autonomy to experiment. We must ensure that our teammates have a place to experiment and also have access to effective tools to quickly test and get feedback. The type of feedback we can get when we're experimenting can be part of the automated systems we already have in place, in particular the automated test suites and metric collection mechanism. Feedback can also come from manual observation and testing. The "sandbox" where developers can experiment will ideally also be extended to effectively integrate with other parts of the system, and get as much feedback as feasible regarding how our system interacts with other systems.
The code is a tool to achieve a goal. As such, we should not grow attached to any piece of code. Not all of the code we will endure indefinitely. Sometimes we have to write short-term code to achieve a short-term object, and that is ok. Sometimes we have to discard some of the code we wrote, and that is okay. We're developers, and we write code to do things. We can also write code to get around roadblocks. In the next sections, we're going to explore some strategies to use the tools at our disposal to get around typical roadblocks.
Identifying External Dependencies
Due to the complexity of enterprise software projects, no code (or almost no code) is built in a vacuum. Many external dependencies need to be considered. This is true for all software projects, from greenfield projects to well-established projects that are in maintenance mode.
The main external dependencies include:
- Infrastructure we don't control.
- APIs that are not ready.
- Common components that we'll consume, for example, libraries that we need to import.
- Organizational processes that need to be followed, such as architectural or security reviews.
Infrastructure Dependencies
Enterprise applications, which are the focus of this book, generally run centrally on infrastructure that must be provisioned and managed. In the age of cloud and Infrastructure as Code (IaC), the provisioning and management of this infrastructure is shifting left and getting closer to development teams. This trend in "self-service" has increased the speed with which applications can be deployed. However, there can always be roadblocks that will slow us down.
Given the dependency, it's vital to incorporate planning for the infrastructure as part of the overall plan of the whole solution. In particular, we need to understand and keep track of:
- What do we need?
- When do we need it?
- How are we going to access it?
In terms of what we need, there can be many different kinds of resources that might be needed during development or at the point in time when we will deploy our application. Some examples:
- Databases
- Servers
- Kubernetes Clusters
- Firewall rules
- CI/CD pipelines
Different resources will be required at different points of the SDLC, so we have to be realistic regarding when particular resources will be required. For this, it's important to map what resources will required at each phase:
- Do we need it to develop?
- Do we need it for automated testing?
- Do we need it for integration?
- Do we need it for production?
The last piece of the puzzle is how are we going to access these resources. Some of the resources will be accessed by our teammates, while other resources will be accessed by a service account or application account. In most organizations, the process for a person to gain access to a resource is different than the process for a service account to gain access. As part of our planning, we must determine what service accounts will be required and what kind of access each service account will require. We must also be aware of what part of the organization will be responsible for creating and managing these. These might be handled by a centralized operations or security team, or it might be handled directly by the development team, for example through an Infrastructure as Code pipeline.
- What infrastructure requirements do we need for our application or component?
- At which phase of the development lifecycle do we require each resource?
- What kinds of access are we going to require to access these resources?
Dependencies on Organizational Processes
While technical dependencies on libraries and frameworks are readily acknowledged, dependencies on organizational processes can often go unnoticed or undermanaged, leading to inefficiencies, delays, and frustration. There are many types of organizational dependencies that are relevant in software development. Some of the main processes are :
- Release and deployment processes: Many teams rely on centralized release and deployment processes managed by other teams. Waiting for approvals, scheduling deployments, and coordinating rollouts can significantly impact development progress.
- Security and compliance reviews: Adhering to security and compliance regulations often involves submitting code for review and approval, adding another layer of dependency and potential delays.
- Manually resting and Q&A Processes: Integrating with manual testing and quality assurance processes requires coordination and collaboration, creating dependencies on their availability and timelines.
- Stakeholder communication and approvals: Obtaining approvals and buy-in from stakeholders can add significant delays and dependencies, particularly in complex organizational structures.
There are many challenges to managing these organizational dependencies:
- Lack of transparency and visibility: Often, dependencies on organizational processes are opaque, making it difficult for developers to anticipate delays and adjust their workflows accordingly.
- Inconsistent and inefficient processes: Manual, paper-based, or poorly designed processes can create bottlenecks and hinder smooth development flow.
- Limited communication and collaboration: Silos between teams and departments can lead to misunderstandings, misaligned expectations, and delays.
As a Senior Software Developer, we must be strategic to manage and mitigate the impact of the processes we go through:
- Increase transparency and visibility: Implement tools and practices to provide developers with real-time visibility into the status of dependencies, allowing them to plan and prioritize their work effectively.
- Automate and streamline processes: Automate as many process steps as possible to remove manual effort and reduce delays. Leverage technology to improve communication and collaboration across teams. Automation of testing goes a long way toward reducing the dependency on the testing and Q&A teams. Automated testing is covered in detail in chapter 5 and chapter 6. Having a properly established Continous Deployment infrastructure that allows us to release with safety will significantly reduce the overhead of dealing with release and deployment processes. We cover Continous Deployment in chapter 22.
- Establish clear communication channels: Define clear communication protocols and expectations to ensure timely updates and address issues promptly. Foster collaboration and build strong relationships with teams responsible for managing dependencies. For example, having regular sprint demos is a great communication channel to ease stakeholder approval and reduce miscommunication.
- Measure and analyze process efficiency: Regularly monitor and analyze the performance of organizational processes to identify bottlenecks and opportunities for improvement. Whenever a process is creating undue frustration or delays, having concrete data is a great way to push back and effect change.
Effective management of organizational dependencies is crucial for ensuring timely and efficient software delivery. By adopting a proactive approach, focusing on transparency, collaboration, and process improvement, software development teams can navigate the complexities of organizational dependencies and deliver successful projects.
Dependency on Custom APIs and Libraries
Many times our system will depend on custom APIs or libraries that other teams are developing. We must keep track of these dependencies and how they will affect our timelines. The primary concern with these dependencies tends to be when it will be ready. This is generally a valid concern for internal dependencies, but we must also go beyond the basic concern for the timeline, and ensure that once built, these dependencies will fulfill our needs. Lack of communication, mismatched expectations, and many other issues could result in a dependency that is finished but does not address our needs. This would lead to reworks, delays, or changes in the architecture.
To help prevent these mismatches, it's advisable to get involved early in the process, for example by being involved in the design process and providing input, or working with the development team to gain early access to API or library to test it as it is being developed.
Working Around Obstacles
No matter how much effort, time, and thought are put into the timelines and cross-team Gantt charts, obstacles are bound to appear along the way. Much like a road construction crew might encounter an unexpected boulder that requires heavy machinery to come in to remove it, the practice of software development is full of unknowns that can turn into obstacles as we try to execute our well-laid-out plans.
These obstacles normally arise out of a combination of the same set of circumstances:
- Mismatched timelines
- Mismatched expectations
- Aspects get overlooked
- Delays
It is our job as Sr. Developers to help our team overcome these obstacles. Having a plan to deal with obstacles related to external dependencies will greatly increase the morale of the team.
A simple, general-purpose plan could look like this:

Identify External Dependencies
External dependencies should be identified as part of the initial design. During this phase, we must assess which dependencies are available already, and what the timeline for those that are not yet available.
Emulators
Once we have identified the dependencies that are not yet available, we can consider using emulators to fill in some of those gaps.
Emulators are especially useful for some kinds of dependencies, in particular, off-the-shelf components such as databases and messaging systems. Using emulators to simulate these components allows us to work if the components haven't been provisioned by the infrastructure team. Emulators can also give us more flexibility, by allowing developers to run the application disconnected from the shared infrastructure, or when the shared infrastructure does not lend itself to supporting multi-tenancy.
How do we define what is an "emulator"? In the strictest sense, an emulator is:
A hardware device or software program that imitates the behavior of another program or device
In the practical sense of the context of this book, an emulator is one of several types of software components:
- A local instance of an external service we depend on (such as a database).
- A software program that imitates another program or service.
- A library that allows us to start a service inside our process.
An emulator will allow us to imitate a piece of software or hardware component that our service will interact with in production. Emulators will have some limitations because they normally do not provide the same behavior and functionality that will be provided by the production component. For example, some emulators will provide less functionality than the real service. The performance characteristics of emulators will never match the real component. We must also remember that the resources that we have in our local laptops or workstations are constrained, so running too many emulators can quickly exhaust them.
Large public cloud providers (such as Amazon Web Services, Microsoft's Azure, and Google Cloud Platform), offer emulators for some of their managed services. These emulators run as standalone processes or inside containers.
For example, AWS provides an emulator for DynamoDB, a managed NoSQL database. Google Cloud Platform offers emulators for Spanner, Pub/Sub, Bigtable, Datastore, and Firestore.
Third parties also offer emulators for other managed services from the big cloud providers.
Depending on your language of choice, it might be possible to run a service that in production would be a standalone component, as part of your process during development. For example, in the JVM ecosystem, you can embedd an instance of the ActiveMQ message broker or the Neo4J database during development or testing. Running these components in-process makes it a lot easier to manage their lifecycle and ensure they're in a known state. This is especially helpful for running unit tests.
Besides not matching the performance of the standalone component, these components that run as part of our process, might not have the full set of functionality. The biggest drawback with these setups is the very limited language compatibility.
- What external emulators or embedded services do we need to support local development?
- What external emulators or embedded services do we need to support the execution of unit tests?
Using Emulators
When using an emulator for development or for running our tests, it's important to think about the developer experience and make it easier for them to get the necessary components up and running.
For example, the emulators can be packaged and distributed in a container. This makes it easier to automate the setup and tear down of the emulators.
This setup and tear-down automation can be achieved with tools like docker-compose, or using orchestrating them with Kubernetes (either in a remote cluster or a local cluster using minikube).
For in-process emulators, the process is very similar to any other library dependency. The libraries required for our "emulator" should be declared as part of our build under the correct scope or profile (for example scoped to test if only needed for our unit tests). We can then add logic for set up and tear down
Mock Missing APIs
When we must rely on APIs that are not ready, we can create mock implementations to keep our team productive. Creating these stop-gap solutions will enable us to keep developing the core functionality, even when the timelines of different teams are not perfectly aligned.
This will result in intermediate code that might have to be thrown away. Or maybe it will result in code that will not be used in production but can still be leveraged for our unit tests. Regardless, writing this code will help us move forward.
Before we can mock an API, we must have a minimum of information to proceed. In particular, we must have an understanding of the basic flow of the API, as well as the data model. If we know what the requests and responses will look like, our mocks will be closer to what the real implementation will look like. One of the objectives of mocking missing APIs is to limit the amount of rework that will required to swap mocked APIs for the real APIs as they become available.
In the early phases of our project, we should work with our peer team to solidify the data model. This can defined as assets that will help both teams move forward and remain in sync. For example, the data model can be specified as an OpenAPI specification, a Protocol Buffers specification, a JSON Schema, or as a shared library with the object model.
If the producer and consumer teams can agree on the contract of the API, mocking will be closer to the final result. However, in cases where there is no agreement, we'll have to use our domain knowledge, Object Oriented best practices, and good judgment to produce a mock that will enable our team to develop the core features while minimizing the risk of targeting a moving API specification.
How to mock APIs
As part of our design, we want to leverage the best Object Oriented patterns. In particular, we want to abstract APIs behind Intefaces and have our business logic should be programmed only against these interfaces. If we leverage a dependency injection framework, it will be easy to swap implementations at runtime without having to change the code.
If we refer back to the three-layer architecture presented in chapter 2, the code access APIs as well as our mock APIs should be located in the bottommost layer:
End-to-End Tests
The code we write is only as good as the quality of its tests. Ease of testing must be ingrained in our development process, and testing should be front and center.
As part of this mentality, we want to create an end-to-end test as soon as possible. The actual scope of the test might be limited in the beginning, and it might not be truly end-to-end, but creating an initial test that covers the system in breadth, even if not in-depth, will allow us to quickly validate our design.
As the implementation of our service evolves, we can keep expanding the scope of this test. This test will in due time become the basis for our integration testing strategy. In [chapter 6] we talk about integration testing in depth.
"Test Message" Pattern
One great pattern to implement this initial end-to-end test is the "Test Message" pattern. The pattern is part "Enterprise Integration Patterns" by Gregor Hohpe and Bobby Woolf.
The Test Data Generator creates messages to be sent to the component for testing.
The Test Message Injector inserts test data into the regular stream of data messages sent to the component. The main role of the injector is to tag messages to differentiate 'real' application messages from test messages. This can be accomplished by inserting a special header field. If we have no control over the message structure, we can try to use special values to indicate test messages (e.g. OrderID = 999999). This changes the semantics of application data by using the same field to represent application data (the actual order number) and control information (this is a test message). Therefore, this approach should be used only as a last resort.
The Test Message Separator extracts the results of test messages from the output stream. This can usually be accomplished by using a Content-Based Router.
The Test Data Verifier compares actual results with expected results and flags an exception if a discrepancy is discovered. Depending on the nature of the test data, the verifier may need access to the original test data.
The "Test Message" pattern is designed to validate the functionality of running systems, we can leverage them from the start of our project to run end-to-end tests. During development, the pattern will allow us to:
- Validate the architecture upfront
- Test new changes as they're integrated
- Smoke test new releases
- Add more cases as needed
The extra logic needed to support test messages can be used during development, when running our integration tests, or when validating the running system in production. This requires the design to take into account the mechanism to process a test message.
Integrate
As the missing dependencies become available, we should aim to exchange the mocks for the real implementations. Having an end-to-end test from the beginning will help us validate that the system keeps functioning correctly as we swap our mocks for real implementations. This level of automated testing will allow our fellow developers to move with more confidence and less risk. We should also expand our testing scenarios to cover the growing functionality.
The code that we wrote to mock external APIs and services can be reused to support our automated testing. Sometimes, some of the code that we wrote to mock these externally will be discarded, and this is a cost that we must assume to keep making progress when timelines are not perfectly aligned.
Regardless of what techniques we decide to use to deal with missing dependencies, it's vital to keep in mind that it is our responsibility as Sr Software Developers to ensure other developers are as productive as possible, because the time of your team is extremely valuable
Tools Referenced
Emulators:
Videos
Keeping the Team Productive
Keeping the Team Productive, continued
Appendix
Metadata
BRANCH_NAME: release
REVISION_ID: 876f817bf9583e75185ff43fa4e0ccb170d6b886
DATE: Sat Mar 9 19:38:07 UTC 2024
Privacy Policy
Introduction
This Privacy Policy ("Policy") outlines how "Senior Developer in 24 hours" ("we," "us," or "our") collects, uses, shares, and protects information gathered from visitors to our website, "srdevin24.com". This Policy applies whenever you access or use our website.
Information We Collect
- Automatically Collected Information: When you interact with our website, we may automatically collect the following:
- Technical Data: IP address, browser type and version, operating system, device information, time zone setting, referring website.
- Usage Data: Pages visited, time spent on pages, links clicked, and other actions taken on the site.
- Google Analytics: We use Google Analytics to understand how visitors use our website. Google Analytics collects information such as your IP address, location data, device information, and browsing behavior. To learn more about Google Analytics' practices, please visit: https://policies.google.com/privacy.
- Cookies and Similar Technologies: We use cookies and similar technologies (like web beacons) to collect usage data and improve our website. A cookie is a small text file stored on your device. For information on managing cookies, refer to the "Your Choices" section.
How We Use Your Information
-
Website Improvement: We analyze usage data to improve the functionality, content, and overall user experience of our website. Understanding Our Audience: We use Google Analytics to understand our website traffic and user demographics. This helps us serve you better. Security: We may use your information to protect our website, systems, users, and to detect/prevent security threats or fraud. How We Share Your Information
-
Google: We share information with Google as part of our use of Google Analytics. Third-Party Service Providers: We may share information with service providers who help us operate our website, such as hosting providers. Legal Compliance: We may disclose your information if legally required, such as in response to a subpoena, court order, or to protect our rights or the rights of others. Business Transactions: In case of a merger, acquisition, or similar transaction, we may transfer your information to the successor organization.
Your Choices
-
Opt-out of Google Analytics: You can opt out of Google Analytics tracking by installing the Google Analytics Opt-out Browser Add-on: https://tools.google.com/dlpage/gaoptout.
-
Managing Cookies: Most browsers allow you to manage or block cookies. Refer to your browser's settings for instructions. Be aware that disabling cookies may hinder website functionality.
Data Security
We employ reasonable security measures to safeguard your information. However, no system is completely secure, and we cannot guarantee absolute security.
Children's Privacy
Our website is not intended for children under the age of 13. We do not knowingly collect personal information from children under 13.
International Visitors
If you are located outside of the United States, please be aware that your information will be transferred to and processed in the United States. Data protection laws in the United States may differ from those in your country. By using our website, you consent to this transfer.
Changes to This Policy
We may update this Privacy Policy periodically. We will notify you of material changes by posting the revised Policy on our website with an updated effective date.
Contact Us
If you have any questions about this Privacy Policy, please contact us.