Keeping the Team Productive
In the previous chapter, we introduced the concept of "Developer Productivity Engineering" or "Developer Experience Engineering", and how automation is a key piece to supporting the developer experience. In this chapter, we talk about how we can support the developers as they navigate the interaction between the code they're writing and the external systems that other teams or organizations manage.
Why is This Important?
In any discipline, project management is hard. And project management in software engineering tends to be even more chaotic and nuanced, due to the shifting nature of IT systems. Software projects tend to rely on complex infrastructure and have many dependencies and access requirements that might not be straightforward to attain. To successfully lead a development effort, it's vital to understand the importance of identifying external dependencies in the Software Development Lifecycle (SDLC). In this chapter, we'll explore different strategies to work around the dependency misalignments that often arise as we're working on complex (or not so complex) software projects.
How Software is Developed
If you have worked in software development for any amount of time, you have likely heard the term "waterfall", "waterfall development", "waterfall model" or a similar term. The waterfall model is sometimes presented as a methodology, but in reality, it's a description of the different operations in the software development process that tend to align themselves. The model was originally described by Winston W. Royce in his 1970 article, "Managing the Development of Large Software Systems".
Royce himself didn't advocate for the waterfall model as an ideal approach. He highlighted its limitations and argued for an iterative approach with feedback loops.
The waterfall model as described by Dr. Royce, is rooted in sequencial tasks where the output of one step feeds into the next step:

This model rarely works as expected, because many situations are common in the day-to-day:
- Mismatched timelines: Different teams have different priorities, and the hard dependencies we have on the work of other teams might not be aligned with the priorities the other team has.
- Mismatched requirements: As different components are built, competing priorities will likely result in mismatched requirements that will have to be reconciled. The product team and the developers might look at the same requirement and understand something different.
- Gaps: Requirement gathering and design exercises are meant to ensure no gaps in the required functionality exist, but as no communication is ever perfect gaps are bound to exist. Those gaps will have to be filled somewhere, most likely by the team that has the greatest need.
- Delays: No matter how well software projects are estimated, there is always the chance of delays. These delays will then have downstream repercussions as other teams have to adjust their own schedules.
- Bugs: Writing software is hard and bugs are to be expected. However, the extent and impact of the bugs are always a big unknown that will have to be addressed.
Given the limitations that the waterfall method brings, a series of lightweight development methodologies arose in the industry. Most of these methodologies can be grouped under the umbrella term "Agile Development". Agile development is supposed to help us overcome the limitations of the waterfall model by :
- Making it easier to adapt to change: Agile methodologies take change for granted and make adapting to constant change part of the methodology. Agile development is especially well-suited for projects where requirements are likely to change. The iterative nature of agile development allows teams to quickly adapt to changes in requirements without disrupting the overall project timeline.
- Improving communication: Agile methodologies recognize that the best way to communicate the progress in the development of a software component is by demonstrating the progress. Constant feedback loops minimize the effort required to adapt to change. Agile development involves regular collaboration between the development team and the customer or product team, which helps to ensure that the final product meets the user's needs. This can lead to increased customer satisfaction and loyalty.
- Reduces risk of defects: Agile development encourages developers to test their code frequently, which helps to catch defects early on. This can save time and money in the long run, as it reduces the need for costly rework. By reducing the size of the changes, the overall risk of introducing defects is reduced by the nature of deploying smaller changes.
- Increases morale of the team: Agile development is a more collaborative and less stressful environment for developers. Seeing constant progress and reducing the uncertainty of long-term plans increases the morale of the team.
Ironically, these lightweight mechanisms make it more likely that development efforts will be completed on time and within budget. Agile methodology helps to ensure that projects are completed on time and within budget. Agile development breaks down projects into smaller, more manageable tasks, which makes it easier to track progress and make adjustments as needed. This can help to reduce the risk of scope creep and delays.
In the real world:
- Schedules slip
- Priorities change
- Things have to be redone
Breaking up projects into small chunks of work that can be completed at short intervals (normally named "sprints") that can deliver meaningful functionality that can be demoed allows us to reduce misunderstandings, limit the amount of rework that must be done, and deliver quicker.
This is not meant to be a full explanation of the Waterfall of Agile methodologies. There are plenty of books already diving into this subject, but as a Sr. Sofware Developer, we must have a solid understanding of how to apply Agile methodologies, and how it counter the most serious issues that occur when operating using a waterfall methodology.
Clear Goals and Expectations
Regardless of the methodology in use, it's vital to ensure that we get clear goals and expectations as move forward. While some very ambitious projects will lack clarity on what the end goal looks like, we must define realistic short-term goals and expectations that will provide feedback for us to clarify and validate the long-term vision that we're working on.
Regular feedback can be gathered from many sources. For example:
- From the code itself: Automated tests and code quality tools can give us concrete data on our progress and the quality of the code we're delivering.
- From stakeholders and SMEs: Performing regular demos (normally after each sprint of work) will give us the best chance to align expectations between the product team and the developers.
- From peer teams: When we have tight dependencies with peer teams, having regular sync meetings with these teams will help us provide and receive feedback as we move forward.
- Within the team: Having daily standups where developers can share what they have done and what they're working on provides an excellent opportunity to provide and receive feedback from other developers who are working on related areas of our application or component. Just remember to park those conversations until after the standup is complete to avoid slowing down everyone in the team!
Regular feedback allows us to shift change left. The sooner we identify an issue, the simpler and cheaper it is to fix.
To make this feedback loop efficient and meaningful, developers must be empowered and have the autonomy to experiment. We must ensure that our teammates have a place to experiment and also have access to effective tools to quickly test and get feedback. The type of feedback we can get when we're experimenting can be part of the automated systems we already have in place, in particular the automated test suites and metric collection mechanism. Feedback can also come from manual observation and testing. The "sandbox" where developers can experiment will ideally also be extended to effectively integrate with other parts of the system, and get as much feedback as feasible regarding how our system interacts with other systems.
The code is a tool to achieve a goal. As such, we should not grow attached to any piece of code. Not all of the code we will endure indefinitely. Sometimes we have to write short-term code to achieve a short-term object, and that is ok. Sometimes we have to discard some of the code we wrote, and that is okay. We're developers, and we write code to do things. We can also write code to get around roadblocks. In the next sections, we're going to explore some strategies to use the tools at our disposal to get around typical roadblocks.
Identifying External Dependencies
Due to the complexity of enterprise software projects, no code (or almost no code) is built in a vacuum. Many external dependencies need to be considered. This is true for all software projects, from greenfield projects to well-established projects that are in maintenance mode.
The main external dependencies include:
- Infrastructure we don't control.
- APIs that are not ready.
- Common components that we'll consume, for example, libraries that we need to import.
- Organizational processes that need to be followed, such as architectural or security reviews.
Infrastructure Dependencies
Enterprise applications, which are the focus of this book, generally run centrally on infrastructure that must be provisioned and managed. In the age of cloud and Infrastructure as Code (IaC), the provisioning and management of this infrastructure is shifting left and getting closer to development teams. This trend in "self-service" has increased the speed with which applications can be deployed. However, there can always be roadblocks that will slow us down.
Given the dependency, it's vital to incorporate planning for the infrastructure as part of the overall plan of the whole solution. In particular, we need to understand and keep track of:
- What do we need?
- When do we need it?
- How are we going to access it?
In terms of what we need, there can be many different kinds of resources that might be needed during development or at the point in time when we will deploy our application. Some examples:
- Databases
- Servers
- Kubernetes Clusters
- Firewall rules
- CI/CD pipelines
Different resources will be required at different points of the SDLC, so we have to be realistic regarding when particular resources will be required. For this, it's important to map what resources will required at each phase:
- Do we need it to develop?
- Do we need it for automated testing?
- Do we need it for integration?
- Do we need it for production?
The last piece of the puzzle is how are we going to access these resources. Some of the resources will be accessed by our teammates, while other resources will be accessed by a service account or application account. In most organizations, the process for a person to gain access to a resource is different than the process for a service account to gain access. As part of our planning, we must determine what service accounts will be required and what kind of access each service account will require. We must also be aware of what part of the organization will be responsible for creating and managing these. These might be handled by a centralized operations or security team, or it might be handled directly by the development team, for example through an Infrastructure as Code pipeline.
- What infrastructure requirements do we need for our application or component?
- At which phase of the development lifecycle do we require each resource?
- What kinds of access are we going to require to access these resources?
Dependencies on Organizational Processes
While technical dependencies on libraries and frameworks are readily acknowledged, dependencies on organizational processes can often go unnoticed or undermanaged, leading to inefficiencies, delays, and frustration. There are many types of organizational dependencies that are relevant in software development. Some of the main processes are :
- Release and deployment processes: Many teams rely on centralized release and deployment processes managed by other teams. Waiting for approvals, scheduling deployments, and coordinating rollouts can significantly impact development progress.
- Security and compliance reviews: Adhering to security and compliance regulations often involves submitting code for review and approval, adding another layer of dependency and potential delays.
- Manually resting and Q&A Processes: Integrating with manual testing and quality assurance processes requires coordination and collaboration, creating dependencies on their availability and timelines.
- Stakeholder communication and approvals: Obtaining approvals and buy-in from stakeholders can add significant delays and dependencies, particularly in complex organizational structures.
There are many challenges to managing these organizational dependencies:
- Lack of transparency and visibility: Often, dependencies on organizational processes are opaque, making it difficult for developers to anticipate delays and adjust their workflows accordingly.
- Inconsistent and inefficient processes: Manual, paper-based, or poorly designed processes can create bottlenecks and hinder smooth development flow.
- Limited communication and collaboration: Silos between teams and departments can lead to misunderstandings, misaligned expectations, and delays.
As a Senior Software Developer, we must be strategic to manage and mitigate the impact of the processes we go through:
- Increase transparency and visibility: Implement tools and practices to provide developers with real-time visibility into the status of dependencies, allowing them to plan and prioritize their work effectively.
- Automate and streamline processes: Automate as many process steps as possible to remove manual effort and reduce delays. Leverage technology to improve communication and collaboration across teams. Automation of testing goes a long way toward reducing the dependency on the testing and Q&A teams. Automated testing is covered in detail in chapter 5 and chapter 6. Having a properly established Continous Deployment infrastructure that allows us to release with safety will significantly reduce the overhead of dealing with release and deployment processes. We cover Continous Deployment in chapter 22.
- Establish clear communication channels: Define clear communication protocols and expectations to ensure timely updates and address issues promptly. Foster collaboration and build strong relationships with teams responsible for managing dependencies. For example, having regular sprint demos is a great communication channel to ease stakeholder approval and reduce miscommunication.
- Measure and analyze process efficiency: Regularly monitor and analyze the performance of organizational processes to identify bottlenecks and opportunities for improvement. Whenever a process is creating undue frustration or delays, having concrete data is a great way to push back and effect change.
Effective management of organizational dependencies is crucial for ensuring timely and efficient software delivery. By adopting a proactive approach, focusing on transparency, collaboration, and process improvement, software development teams can navigate the complexities of organizational dependencies and deliver successful projects.
Dependency on Custom APIs and Libraries
Many times our system will depend on custom APIs or libraries that other teams are developing. We must keep track of these dependencies and how they will affect our timelines. The primary concern with these dependencies tends to be when it will be ready. This is generally a valid concern for internal dependencies, but we must also go beyond the basic concern for the timeline, and ensure that once built, these dependencies will fulfill our needs. Lack of communication, mismatched expectations, and many other issues could result in a dependency that is finished but does not address our needs. This would lead to reworks, delays, or changes in the architecture.
To help prevent these mismatches, it's advisable to get involved early in the process, for example by being involved in the design process and providing input, or working with the development team to gain early access to API or library to test it as it is being developed.
Working Around Obstacles
No matter how much effort, time, and thought are put into the timelines and cross-team Gantt charts, obstacles are bound to appear along the way. Much like a road construction crew might encounter an unexpected boulder that requires heavy machinery to come in to remove it, the practice of software development is full of unknowns that can turn into obstacles as we try to execute our well-laid-out plans.
These obstacles normally arise out of a combination of the same set of circumstances:
- Mismatched timelines
- Mismatched expectations
- Aspects get overlooked
- Delays
It is our job as Sr. Developers to help our team overcome these obstacles. Having a plan to deal with obstacles related to external dependencies will greatly increase the morale of the team.
A simple, general-purpose plan could look like this:

Identify External Dependencies
External dependencies should be identified as part of the initial design. During this phase, we must assess which dependencies are available already, and what the timeline for those that are not yet available.
Emulators
Once we have identified the dependencies that are not yet available, we can consider using emulators to fill in some of those gaps.
Emulators are especially useful for some kinds of dependencies, in particular, off-the-shelf components such as databases and messaging systems. Using emulators to simulate these components allows us to work if the components haven't been provisioned by the infrastructure team. Emulators can also give us more flexibility, by allowing developers to run the application disconnected from the shared infrastructure, or when the shared infrastructure does not lend itself to supporting multi-tenancy.
How do we define what is an "emulator"? In the strictest sense, an emulator is:
A hardware device or software program that imitates the behavior of another program or device
In the practical sense of the context of this book, an emulator is one of several types of software components:
- A local instance of an external service we depend on (such as a database).
- A software program that imitates another program or service.
- A library that allows us to start a service inside our process.
An emulator will allow us to imitate a piece of software or hardware component that our service will interact with in production. Emulators will have some limitations because they normally do not provide the same behavior and functionality that will be provided by the production component. For example, some emulators will provide less functionality than the real service. The performance characteristics of emulators will never match the real component. We must also remember that the resources that we have in our local laptops or workstations are constrained, so running too many emulators can quickly exhaust them.
Large public cloud providers (such as Amazon Web Services, Microsoft's Azure, and Google Cloud Platform), offer emulators for some of their managed services. These emulators run as standalone processes or inside containers.
For example, AWS provides an emulator for DynamoDB, a managed NoSQL database. Google Cloud Platform offers emulators for Spanner, Pub/Sub, Bigtable, Datastore, and Firestore.
Third parties also offer emulators for other managed services from the big cloud providers.
Depending on your language of choice, it might be possible to run a service that in production would be a standalone component, as part of your process during development. For example, in the JVM ecosystem, you can embedd an instance of the ActiveMQ message broker or the Neo4J database during development or testing. Running these components in-process makes it a lot easier to manage their lifecycle and ensure they're in a known state. This is especially helpful for running unit tests.
Besides not matching the performance of the standalone component, these components that run as part of our process, might not have the full set of functionality. The biggest drawback with these setups is the very limited language compatibility.
- What external emulators or embedded services do we need to support local development?
- What external emulators or embedded services do we need to support the execution of unit tests?
Using Emulators
When using an emulator for development or for running our tests, it's important to think about the developer experience and make it easier for them to get the necessary components up and running.
For example, the emulators can be packaged and distributed in a container. This makes it easier to automate the setup and tear down of the emulators.
This setup and tear-down automation can be achieved with tools like docker-compose, or using orchestrating them with Kubernetes (either in a remote cluster or a local cluster using minikube).
For in-process emulators, the process is very similar to any other library dependency. The libraries required for our "emulator" should be declared as part of our build under the correct scope or profile (for example scoped to test if only needed for our unit tests). We can then add logic for set up and tear down
Mock Missing APIs
When we must rely on APIs that are not ready, we can create mock implementations to keep our team productive. Creating these stop-gap solutions will enable us to keep developing the core functionality, even when the timelines of different teams are not perfectly aligned.
This will result in intermediate code that might have to be thrown away. Or maybe it will result in code that will not be used in production but can still be leveraged for our unit tests. Regardless, writing this code will help us move forward.
Before we can mock an API, we must have a minimum of information to proceed. In particular, we must have an understanding of the basic flow of the API, as well as the data model. If we know what the requests and responses will look like, our mocks will be closer to what the real implementation will look like. One of the objectives of mocking missing APIs is to limit the amount of rework that will required to swap mocked APIs for the real APIs as they become available.
In the early phases of our project, we should work with our peer team to solidify the data model. This can defined as assets that will help both teams move forward and remain in sync. For example, the data model can be specified as an OpenAPI specification, a Protocol Buffers specification, a JSON Schema, or as a shared library with the object model.
If the producer and consumer teams can agree on the contract of the API, mocking will be closer to the final result. However, in cases where there is no agreement, we'll have to use our domain knowledge, Object Oriented best practices, and good judgment to produce a mock that will enable our team to develop the core features while minimizing the risk of targeting a moving API specification.
How to mock APIs
As part of our design, we want to leverage the best Object Oriented patterns. In particular, we want to abstract APIs behind Intefaces and have our business logic should be programmed only against these interfaces. If we leverage a dependency injection framework, it will be easy to swap implementations at runtime without having to change the code.
If we refer back to the three-layer architecture presented in chapter 2, the code access APIs as well as our mock APIs should be located in the bottommost layer:

End-to-End Tests
The code we write is only as good as the quality of its tests. Ease of testing must be ingrained in our development process, and testing should be front and center.
As part of this mentality, we want to create an end-to-end test as soon as possible. The actual scope of the test might be limited in the beginning, and it might not be truly end-to-end, but creating an initial test that covers the system in breadth, even if not in-depth, will allow us to quickly validate our design.
As the implementation of our service evolves, we can keep expanding the scope of this test. This test will in due time become the basis for our integration testing strategy. In [chapter 6] we talk about integration testing in depth.
"Test Message" Pattern
One great pattern to implement this initial end-to-end test is the "Test Message" pattern. The pattern is part "Enterprise Integration Patterns" by Gregor Hohpe and Bobby Woolf.
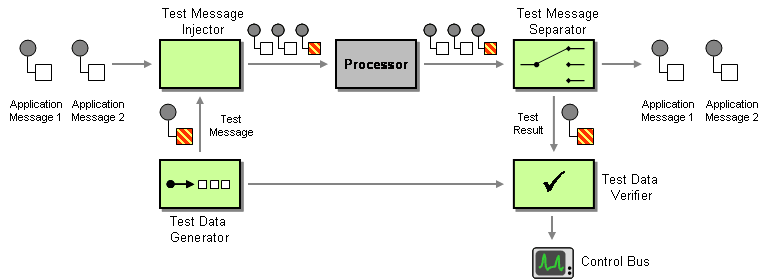
The Test Data Generator creates messages to be sent to the component for testing.
The Test Message Injector inserts test data into the regular stream of data messages sent to the component. The main role of the injector is to tag messages to differentiate 'real' application messages from test messages. This can be accomplished by inserting a special header field. If we have no control over the message structure, we can try to use special values to indicate test messages (e.g. OrderID = 999999). This changes the semantics of application data by using the same field to represent application data (the actual order number) and control information (this is a test message). Therefore, this approach should be used only as a last resort.
The Test Message Separator extracts the results of test messages from the output stream. This can usually be accomplished by using a Content-Based Router.
The Test Data Verifier compares actual results with expected results and flags an exception if a discrepancy is discovered. Depending on the nature of the test data, the verifier may need access to the original test data.
The "Test Message" pattern is designed to validate the functionality of running systems, we can leverage them from the start of our project to run end-to-end tests. During development, the pattern will allow us to:
- Validate the architecture upfront
- Test new changes as they're integrated
- Smoke test new releases
- Add more cases as needed
The extra logic needed to support test messages can be used during development, when running our integration tests, or when validating the running system in production. This requires the design to take into account the mechanism to process a test message.
Integrate
As the missing dependencies become available, we should aim to exchange the mocks for the real implementations. Having an end-to-end test from the beginning will help us validate that the system keeps functioning correctly as we swap our mocks for real implementations. This level of automated testing will allow our fellow developers to move with more confidence and less risk. We should also expand our testing scenarios to cover the growing functionality.
The code that we wrote to mock external APIs and services can be reused to support our automated testing. Sometimes, some of the code that we wrote to mock these externally will be discarded, and this is a cost that we must assume to keep making progress when timelines are not perfectly aligned.
Regardless of what techniques we decide to use to deal with missing dependencies, it's vital to keep in mind that it is our responsibility as Sr Software Developers to ensure other developers are as productive as possible, because the time of your team is extremely valuable
Tools Referenced
Emulators: